实验三、基于大数据集的数据库操作
1. 目的与要求
本实验主要是熟悉ORACLE的基于大数据集(记录达到千万级)的相关数据库操作包括生成海量测试数据的更新操作、基于海量数据的索引维护、表空间、分区、视图、序列及相关的统计分析。
2. 操作环境
- 硬件:主频2GHz以上服务器(内存2GB以上、硬件空闲2.2GB以上),主频1GHz以上微机,内存1GB以上。
- 软件:WINDOWS XP/2000/2003/或Win7/Win8/Win10等。如操作系统是 SERVER版, 可安装ORACLE/9i/10g/11g/12C FOR NT/WINDOWS(注意有32位与64位的区别,可选企业版); 如果Windows非server如XP/win7等,安装时请选择个人版(PERSONAL),注意安装时要有兼容性设置与用管理员运行。安装过程中需要关注系统预定义的账号SYS与SYSTEM的密码设置。
3. 实验内容
分析整个实验内容,在实验开始前写一个记录时间的过程有利于实验的顺利进行
建立一个t_time_consume_D312表,字段如下
| event | start_time | end_time | time_consume |
|---|---|---|---|
set serveroutpu on;
set linesize 500;
-- 0.创建记录时间过程
drop table t_time_consume_D312;
create table t_time_consume_D312 (
event varchar2(128) primary key,
start_time timestamp,
end_time timestamp,
time_consume interval day to second
);
col event format a30;
col start_time format a33;
col end_time format a33;
col time_consume format a20;
drop synonym t_time;
create synonym t_time for t_time_consume_D312;
create or replace procedure p_record_time_D312
(
p_event in varchar2,
p_flag in varchar2
)
as
v_start_time timestamp;
v_end_time timestamp;
v_time interval day to second;
begin
if p_flag = 'start' then
-- 插入开始时间
select systimestamp into v_start_time from dual;
insert into t_time(event, start_time) values(p_event, v_start_time);
else
-- 更新终止时间与时间开销,打印输出
select systimestamp into v_end_time from dual;
select start_time into v_start_time from t_time where event = p_event;
select (v_end_time - v_start_time) day(2) to second into v_time from dual;
update t_time set end_time = v_end_time, time_consume = v_time where event = p_event;
dbms_output.put_line(p_event || '耗时: ' || v_time);
end if;
end;
/
show error;
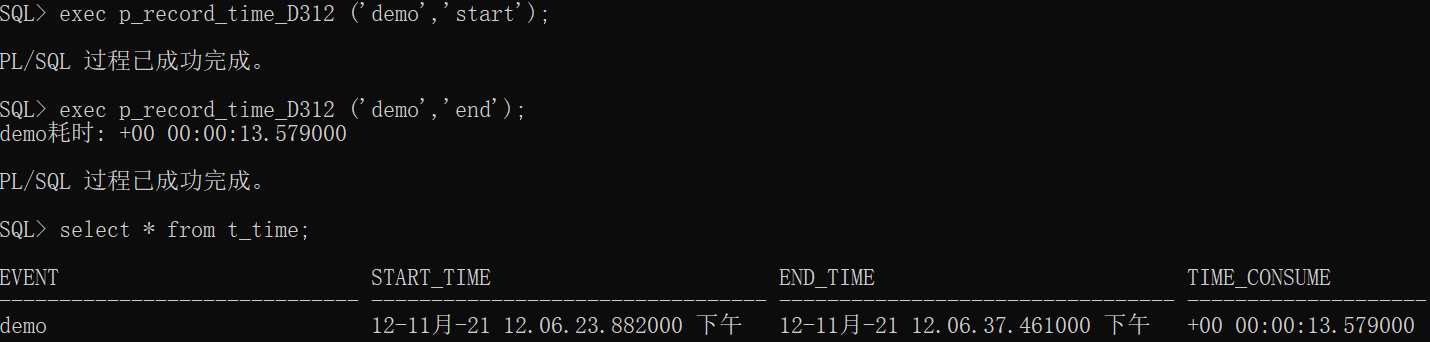
exec p_record_time_D312 ('demo','start');
-- 过若干秒
exec p_record_time_D312 ('demo','end');
select * from t_time;
3. 1 生成数据集
以常用“名字大全”与“百家姓”数据集为基础,生成不小于1千万条stud记录
要求
- 姓名的重复率不超过10%
- 学号以ABCD19EFGH为格式模板,即其中19是固定的,AB为从01到80,CD为从01到90,EF为01到50,GH为01到32
- 性别中,男、女占比为99%到99.5%
- TEL与E-mail不作要求,但不能全空
- Birthday要求从‘19940101’到‘19990731’分布
- 要求记录ORACLE数据文件的大小变化
主要思路
- 生成姓名表
t_name - 生成学号表
t_sno - 随机生成其他字段表
t_random - 将三个表合并即得最终学生信息表
t_stud_info;注意此处不含任何约束;在插入所有数据后统一添加
3. 1. 1 导入姓名相关数据
-- 1. 导入姓名与相关数据
drop table t_name1;
create table t_name1(last_name varchar2(32));
drop table t_name2;
create table t_name2(first_name varchar2(32));
drop table t_common_name;
create table t_common_name(name varchar2(32));
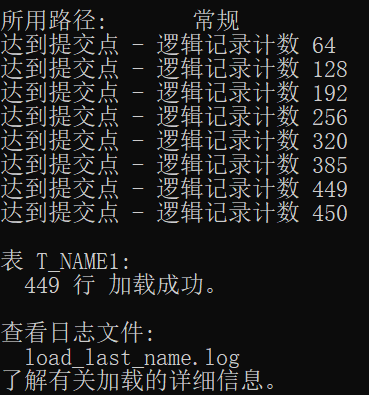
------- load_last_name.ctl -------
LOAD DATA
INFILE 'D:\Messy\Experiment\last_name.CSV'
APPEND
INTO TABLE t_name1
FIELDS TERMINATED BY ','
(last_name)
------- cmd -------
sqlldr userid=C##U_LZC_D312/sys control='D:\Messy\Experiment\大型数据库\OraExp3_D312\load_last_name.ctl'
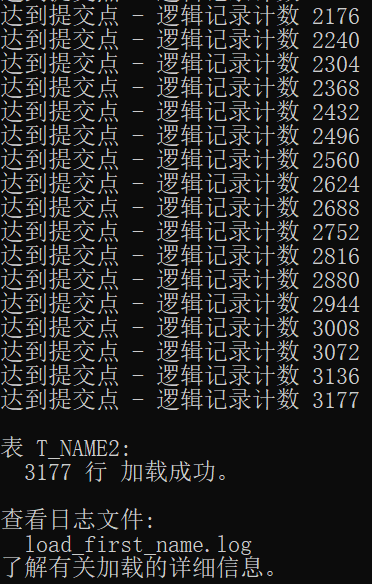
------- load_first_name.ctl -------
LOAD DATA
INFILE 'D:\Messy\Experiment\first_name.CSV'
APPEND
INTO TABLE t_name2
FIELDS TERMINATED BY ','
(first_name)
------- cmd -------
sqlldr userid=C##U_LZC_D312/sys control='D:\Messy\Experiment\大型数据库\OraExp3_D312\load_first_name.ctl'
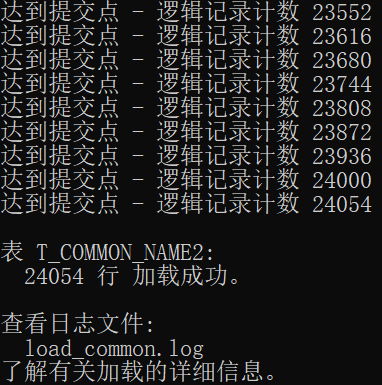
------- load_common.ctl -------
OPTIONS(SKIP=1) --跳过第一行
LOAD DATA
INFILE 'D:\Messy\Experiment\common.CSV'
APPEND
INTO TABLE t_common_name
FIELDS TERMINATED BY ','
(virtual_column FILLER, name)
------- cmd -------
sqlldr userid=C##U_LZC_D312/sys control='D:\Messy\Experiment\大型数据库\OraExp3_D312\load_common.ctl'
-- 删去复姓
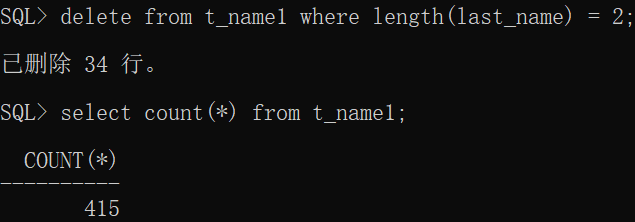
select count(*) from t_name1 where length(last_name) = 2;
delete from t_name1 where length(last_name) = 2;
select count(*) from t_name1;
3. 1. 2 生成姓名
从姓氏表选随机取 400 条记录,从常用名表分别随机选取 150 和 200 条记录,通过全排列生成 400﹡150﹡250=1500,0000 个名字。再插入常用姓名表即可,故最终有 1502, 4054 条名字记录
步骤
- 创建三个视图,分别对应上述的 400, 150, 250,简化语句以及不必要的开销
- 创建表
t_name - 插入三个视图的笛卡尔积
- 插入常用姓名表
-- 2. 创建姓名表
drop view v_name1;
drop view v_name2;
drop view v_name3;
-- 随机选择
delete from t_time where event='生成名字';
exec p_record_time_D312 ('生成名字','start');
create view v_name1 as select last_name n1 from (select distinct last_name from t_name1 order by dbms_random.value) where rownum <= 400;
create view v_name2 as select first_name n2 from (select distinct first_name from t_name2 order by dbms_random.value) where rownum <= 150;
create view v_name3 as select first_name n3 from (select distinct first_name from t_name2 order by dbms_random.value) where rownum <= 250;
set timing on;
set serveroutpu on;
-- 笛卡尔积
drop table t_name;
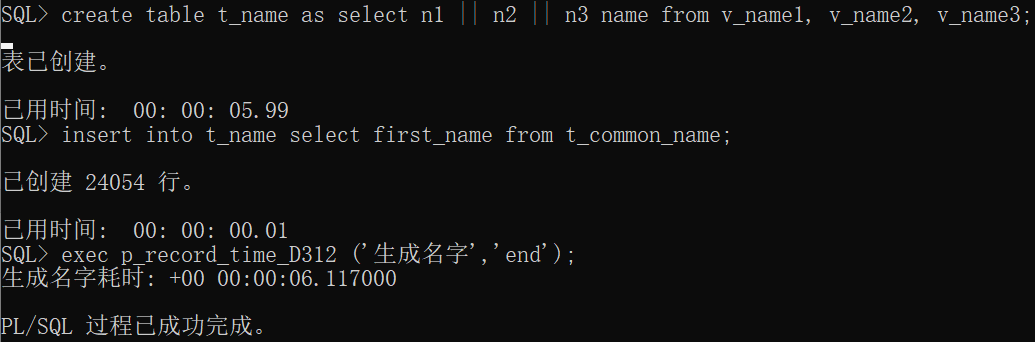
create table t_name as select n1 || n2 || n3 name from v_name1, v_name2, v_name3;
-- 插入常用姓名
insert into t_name select first_name from t_common_name;
exec p_record_time_D312 ('生成名字','end');
3. 1. 3 生成学号
提高insert的几个Tip
insert-select:保证所有在RAM里面
Each query will have its own PGA [Program global area] which is basically RAM available to each query. If this this area is not sufficient to return query results then SQL engine starts using Global temp tablespace which is like hard disk and query starts becoming slow. If data needed by query is so huge that even temp area is not sufficient then you will tablespace error.
So always design query so that it stays in PGA else its a Red flag.
-
/*+ APPEND */ -
NOLOGGING
步骤
- 创建四个表,分别对应AB CD EF GH 学号部分;前缀形式
- 按GH EF CD AB顺序生成学号表
PS:下述提供两种写法
-- 3. 生成学号
exec p_record_time_D312 ('生成学号','start');
-- 存最终sno
drop table t_sno_ab;
drop table t_sno_cd;
drop table t_sno_ef;
drop table t_sno_gh;
-- 由于有前导0,故存成string,同时降低存储开销
create table t_sno_ab(sno varchar2(32));
create table t_sno_cd(sno number(8));
create table t_sno_ef(sno number(8));
create table t_sno_gh(sno number(2));
declare
i int;
begin
insert into t_sno_gh select level from dual connect by level <= 32;
for i in 1..50 loop
insert /*+ append */ into t_sno_ef select 190000+i*100+t_sno_gh.sno from t_sno_gh;
commit;
end loop;
for i in 1..90 loop
insert /*+ append */ into t_sno_cd select i*1000000+t_sno_ef.sno from t_sno_ef;
commit;
end loop;
for i in 1..100 loop
insert /*+ append */ into t_sno_ab select substr(10000000000+i*100000000+t_sno_cd.sno,2,10) from t_sno_cd;
commit;
end loop;
end;
/
exec p_record_time_D312 ('生成学号','end');
----------------- 一种更简便的写法 ------------------
exec p_record_time_D312 ('生成学号2','start');
-- 存最终sno
drop table t_sno_ab;
drop table t_sno_cd;
drop table t_sno_ef;
drop table t_sno_gh;
create table t_sno_ab(sno varchar2(32));
create table t_sno_cd(sno number(8));
create table t_sno_ef(sno number(8));
create table t_sno_gh(sno number(2));
insert /*+ append */ into t_sno_gh select level from dual connect by level <= 32;
commit;
insert /*+ append */ into t_sno_ef select 190000+i*100+t_sno_gh.sno from t_sno_gh, (select level i from dual connect by level <= 50);
commit;
insert /*+ append */ into t_sno_cd select i*1000000+t_sno_ef.sno from t_sno_ef, (select level i from dual connect by level <= 90);
commit;
insert /*+ append */ into t_sno_ab select substr(10000000000+i*100000000+t_sno_cd.sno,2,10) from t_sno_cd, (select level i from dual connect by level <= 100);
commit;
exec p_record_time_D312 ('生成学号2','end');


3. 1. 4 生成剩余随机字段
- 性别:随机选择1~1000的数x,当 $x<498$ 时,为男性,反之当 $x<995$ 时为女性,其余情况记作缺失
- 电话:事先存储常见电话3位前缀,然后剩下的8位数字随机生成
- 邮箱:事先存储常见的邮箱名,数字部分随机生成
- 生日:随机生成
1994-01-01到1999-07-31的生日
-- 4. 生成剩余随机字段
-- 性别
create or replace function f_get_sex return varchar2
as
v_num number;
v_sex varchar2(8);
begin
select dbms_random.value(1,1000) into v_num from dual;
if v_num < 498 then
v_sex := '男';
elsif v_num < 995 then
v_sex := '女';
else
v_sex := '缺失';
end if;
return v_sex;
end;
/
-- 电话
-- 辅助表:存储电话前三位
drop table t_tel_head;
create table t_tel_head(htel varchar2(4));
declare
type htel_array is varray(14) of t_tel_head.htel%type;
htels htel_array := htel_array('132', '135', '138', '139', '150', '151', '153', '156', '177', '178', '180', '183', '186', '188');
begin
for i in 1..14 loop
insert into t_tel_head values(htels(i));
end loop;
end;
/
select * from t_tel_head;
create or replace function f_get_tel return varchar2
is
v_tel varchar2(32);
v_htel varchar2(4);
v_ttel varchar2(16);
begin
-- 随机选一行模板
select htel into v_htel from (select htel from t_tel_head order by dbms_random.value ) where rownum = 1;
-- 上面不能写成:select htel from t_tel_head where rownum = 1 order by dbms_random.value; 因为这是先取一个数然后打乱
-- 随机生成剩余手机号
select substr(cast(dbms_random.value as varchar2(32)),5,8) into v_ttel from dual;
v_tel := v_htel || v_ttel;
return v_tel;
end;
/
show error;
-- 邮箱
-- 辅助表:常见邮箱
drop table t_email;
create table t_email_suffix(email_suffix varchar2(32));
declare
type email_suffix_array is varray(7) of t_email_suffix.email_suffix%type;
es email_suffix_array := email_suffix_array ('qq', 'gmail', 'ymail', '126', '169', 'outlook', 'csu');
begin
for i in 1..7 loop
insert into t_email_suffix values(es(i));
end loop;
end;
/
select * from t_email_suffix;
create or replace function f_get_email return varchar2
is
v_email_suffix varchar2(32);
v_email_head varchar2(32);
v_email varchar2(32);
begin
select email_suffix into v_email_suffix from (select email_suffix from t_email_suffix order by dbms_random.value ) where rownum = 1;
select substr(cast(dbms_random.value as varchar2(32)),4,11) into v_email_head from dual;
v_email := v_email_head || '@' || v_email_suffix || '.com';
return v_email;
end;
/
-- 生日
create or replace function f_get_birth return date
is
birth date;
begin
select to_date(
trunc(
dbms_random.value(to_char(date '1994-01-01', 'J'),
to_char(date '1999-07-31','J')
)
)
, 'J') into birth from dual;
return birth;
end;
/
Test
-- 测试
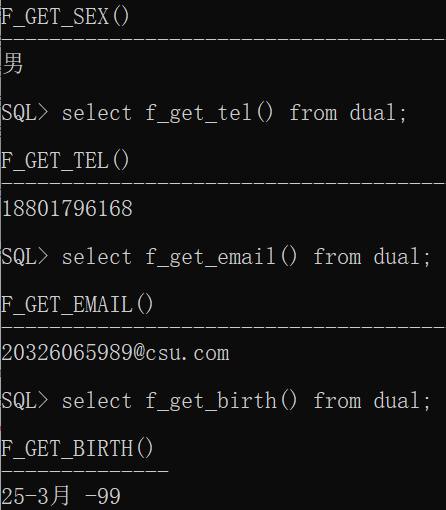
select f_get_sex() from dual;
select f_get_tel() from dual;
select f_get_email() from dual;
select f_get_birth() from dual;
生成随机生成的字段
-- 生成随机生成的字段
set timing on;
delete from t_time where event = '生成随机字段';
exec p_record_time_D312 ('生成随机字段','start');
drop table t_random;
create table t_random(
sex varchar2(32),
tel varchar2(32),
email varchar2(32),
birthday date
);
insert /*+ append */ into t_random NOLOGGING select f_get_sex(), f_get_tel(), f_get_email(), f_get_birth() from xmltable('1 to 14400000');
commit;
exec p_record_time_D312 ('生成随机字段','end');

3. 1. 5 生成数据集
生成学生信息表
-- 生成最终数据集
set timing on;
delete from t_time where event = '生成最终数据集';
exec p_record_time_D312 ('生成最终数据集','start');
-- 生成不含主键的学生信息表
drop table t_stud_info_D312;
create table t_stud_info_D312(
sno varchar2(32),
sname varchar2(32),
sex varchar2(32),
tel varchar2(32),
email varchar2(32),
birthday date
);
drop synonym t_stud;
create synonym t_stud for t_stud_info_D312;
insert into t_stud
select
A.sno, B.name, C.sex, C.tel, C.email, C.birthday
from
(select t_sno_ab.*, rownum rn1 from t_sno_ab) A,
(select t_name.*, rownum rn2 from t_name) B,
(select t_random.*, rownum rn3 from t_random) C
where rn1 = rn2 and rn2 = rn3;
exec p_record_time_D312 ('生成最终数据集','end');
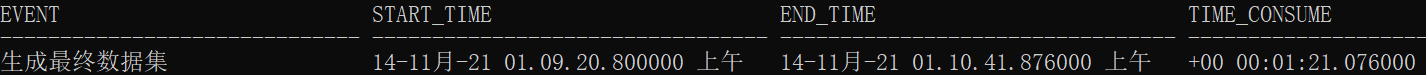
- 用时明细
-- 用时明细
select * from t_time;

- 追踪数据文件大小变化
-- 查看数据文件路径
select tablespace_name,file_id,file_name from dba_data_files order by 1,2;


3. 2 追踪主键的影响
对比 stud 有主键与没有主键情形下生成记录的时间与数据文件大小追踪
3. 2. 1 无主键
见3. 1. 5
3. 2. 2 有主键
-- 生成有主键的数据集
set timing on;
delete from t_time where event = '生成有主键最终数据集';
exec p_record_time_D312 ('生成有主键最终数据集','start');
-- 生成含主键的学生信息表
drop table t_pk_stud_info_D312;
create table t_pk_stud_info_D312(
sno varchar2(32) primary key,
sname varchar2(32),
sex varchar2(32),
tel varchar2(32),
email varchar2(32),
birthday date
);
drop synonym t_pk_stud;
create synonym t_pk_stud for t_pk_stud_info_D312;
insert into t_pk_stud
select
A.sno, B.name, C.sex, C.tel, C.email, C.birthday
from
(select t_sno_ab.*, rownum rn1 from t_sno_ab) A,
(select t_name.*, rownum rn2 from t_name) B,
(select t_random.*, rownum rn3 from t_random) C
where rn1 = rn2 and rn2 = rn3;
exec p_record_time_D312 ('生成有主键最终数据集','end');

- 追踪数据文件大小变化

对比发现,存储空间比无主键的多了约10倍
- 时间明细

为完整性,在此处补上潜在的约束
-- 添加约束
exec p_record_time_D312 ('添加约束','start');
alter table t_stud_info_D312 add constraint pk_sno primary key(sno);
alter table t_stud_info_D312 add constraint ck_sex check(sex in ('男', '女', '缺失'));
alter table t_stud_info_D312 add constraint ck_email check(email like '%@%.%');
alter table t_stud_info_D312 add constraint ck_birth check(birthday between date '1994-01-01' and date '1999-07-31');
exec p_record_time_D312 ('添加约束','end');
3. 3 - 3.4 索引对性能的影响
索引建立前
- 查询某一姓名、某一姓、某一名的时间
- 分姓、分名的记录数统计时间
-- 查询
set serveroutpu on;
set timing on;
set autotrace on;
delete from t_time where event='无索引查找姓名';
exec p_record_time_D312 ('无索引查找姓名','start');
select sname from t_stud where sname='叶令官';
exec p_record_time_D312 ('无索引查找姓名','end');
delete from t_time where event='无索引查找姓';
exec p_record_time_D312 ('无索引查找姓','start');
select sname from t_stud where sname like '叶__';
exec p_record_time_D312 ('无索引查找姓','end');
delete from t_time where event='无索引查找名';
exec p_record_time_D312 ('无索引查找名','start');
select sname from t_stud where sname like '_令官';
exec p_record_time_D312 ('无索引查找名','end');
delete from t_time where event='无索引统计姓';
exec p_record_time_D312 ('无索引统计姓','start');
select count(*) from t_stud where sname like '叶__';
exec p_record_time_D312 ('无索引统计姓','end');
delete from t_time where event='无索引统计名1';
exec p_record_time_D312 ('无索引统计名1','start');
select count(*) from t_stud where sname like '_令_';
exec p_record_time_D312 ('无索引统计名1','end');
delete from t_time where event='无索引统计名2';
exec p_record_time_D312 ('无索引统计名2','start');
select count(*) from t_stud where sname like '__官';
exec p_record_time_D312 ('无索引统计名2','end');
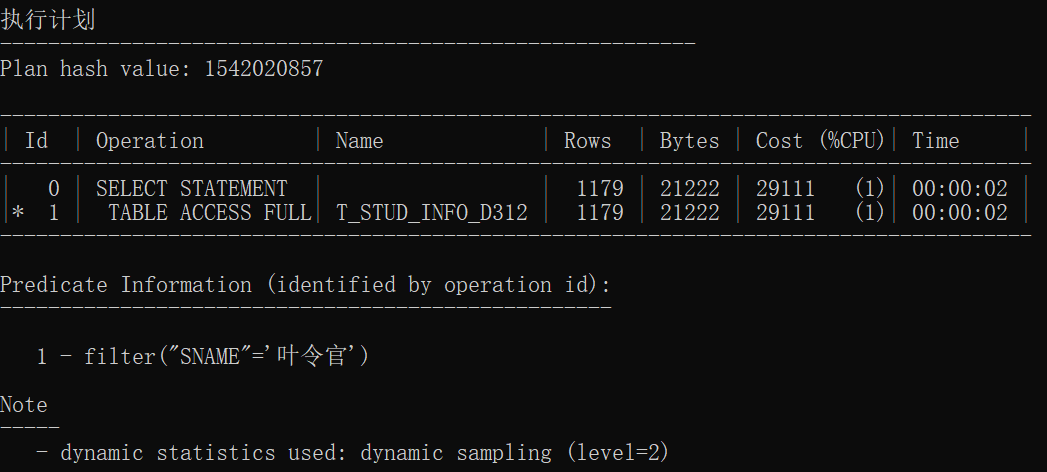
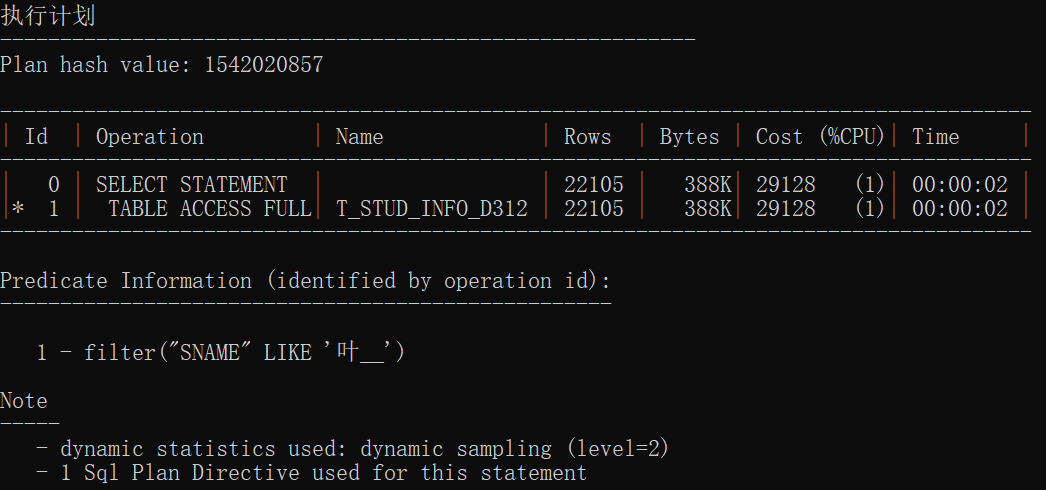
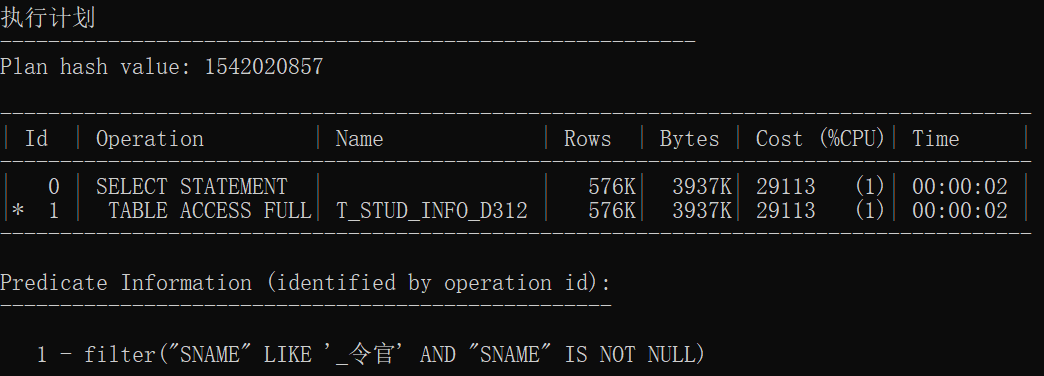
统计信息的执行计划
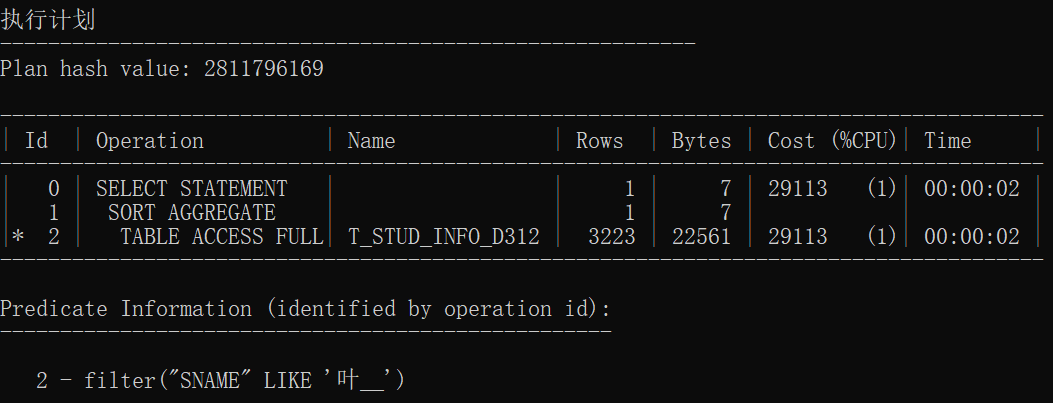
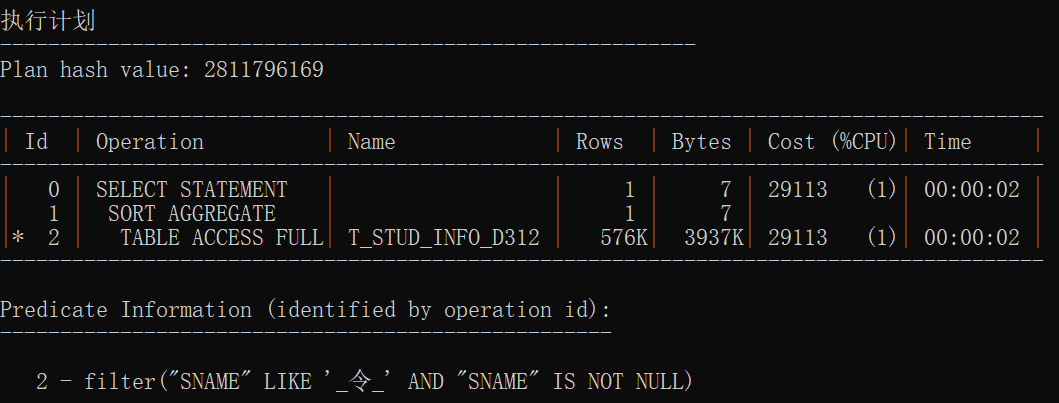
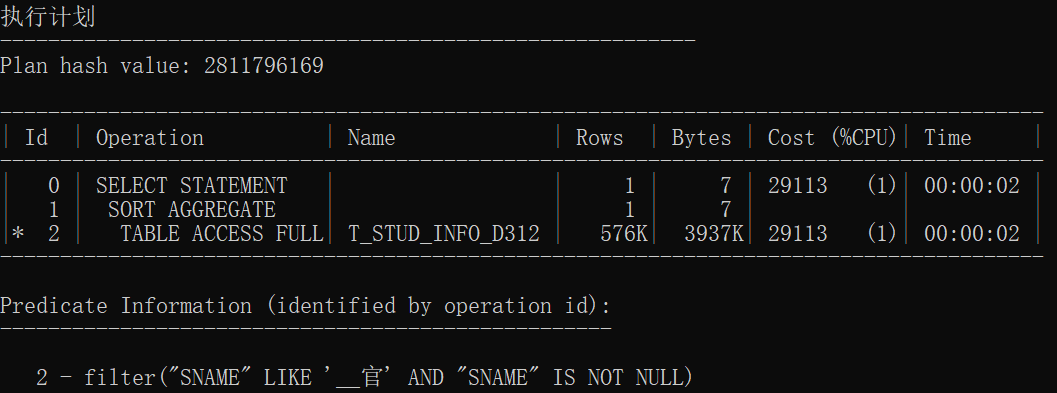
索引建立后
- 查询某一姓名、某一姓、某一名的时间
- 分姓、分名的记录数统计时间
-- 建立索引
drop index index_name_D312;
delete from t_time where event='建立索引';
exec p_record_time_D312 ('建立索引','start');
create index index_name_D312 on t_stud_info_D312(sname);
exec p_record_time_D312 ('建立索引','end');
-- 查询
set serveroutpu on;
set timing on;
set autotrace on;
delete from t_time where event='有索引查找姓名';
exec p_record_time_D312 ('有索引查找姓名','start');
select sname from t_stud where sname='叶令官';
exec p_record_time_D312 ('有索引查找姓名','end');
delete from t_time where event='有索引查找姓';
exec p_record_time_D312 ('有索引查找姓','start');
select sname from t_stud where sname like '叶__';
exec p_record_time_D312 ('有索引查找姓','end');
delete from t_time where event='有索引查找名';
exec p_record_time_D312 ('有索引查找名','start');
select sname from t_stud where sname like '_令官';
exec p_record_time_D312 ('有索引查找名','end');
delete from t_time where event='有索引统计姓';
exec p_record_time_D312 ('有索引统计姓','start');
select count(*) from t_stud where sname like '叶__';
exec p_record_time_D312 ('有索引统计姓','end');
delete from t_time where event='有索引统计名1';
exec p_record_time_D312 ('有索引统计名1','start');
select count(*) from t_stud where sname like '_令_';
exec p_record_time_D312 ('有索引统计名1','end');
delete from t_time where event='有索引统计名2';
exec p_record_time_D312 ('有索引统计名2','start');
select count(*) from t_stud where sname like '__官';
exec p_record_time_D312 ('有索引统计名2','end');
set autotrace off;
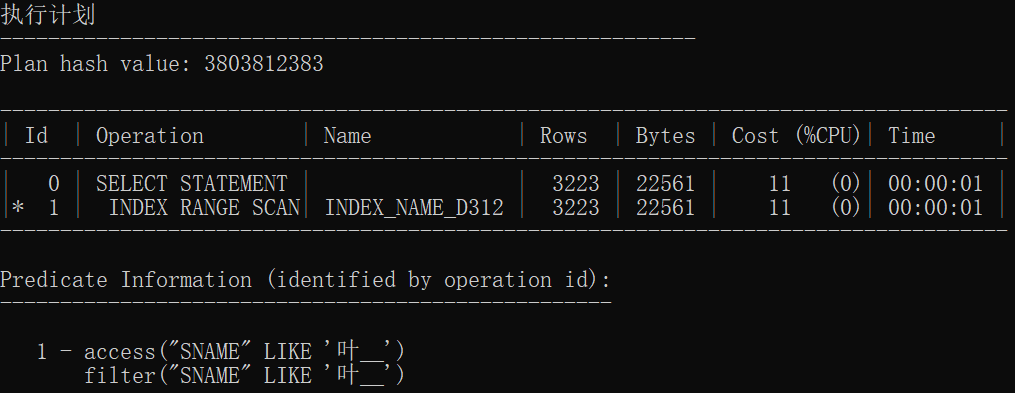
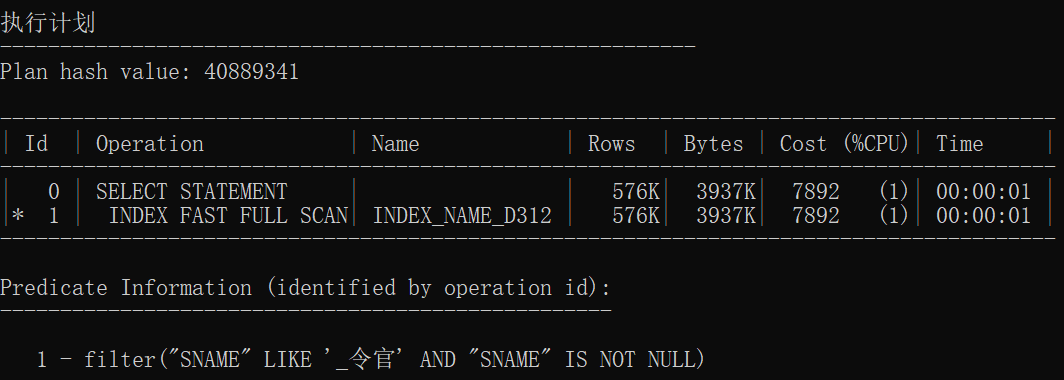
统计信息
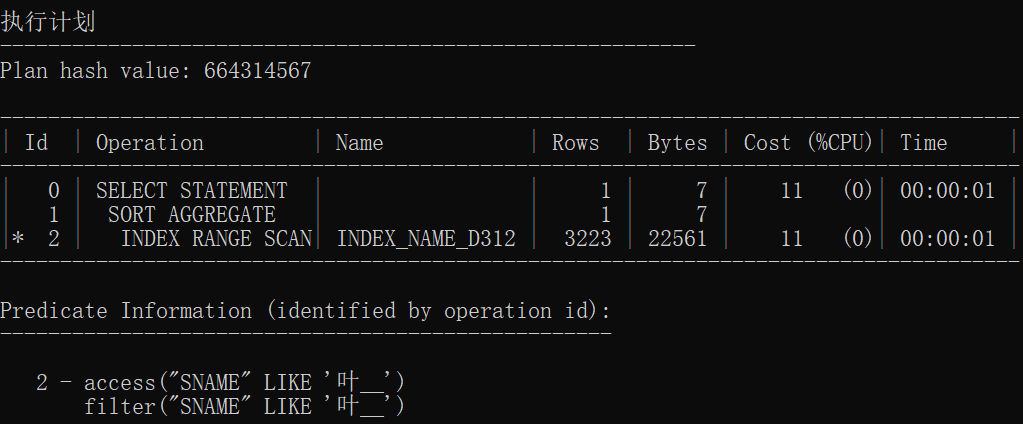
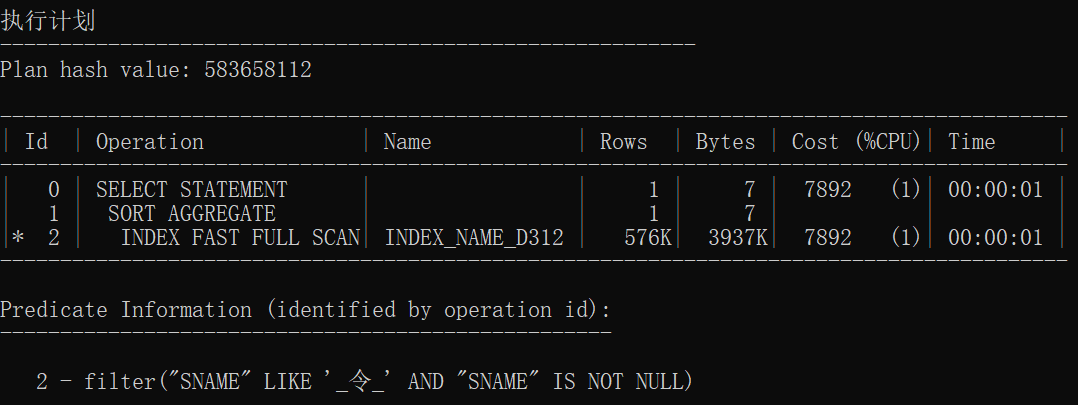
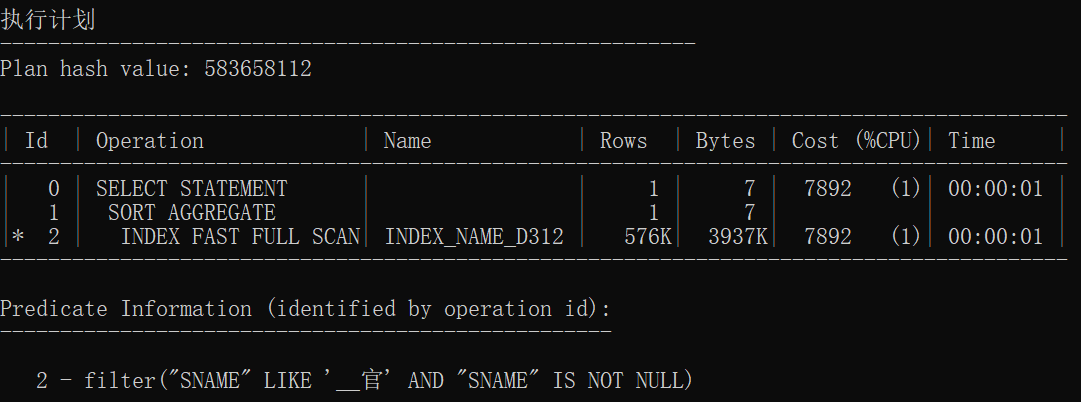
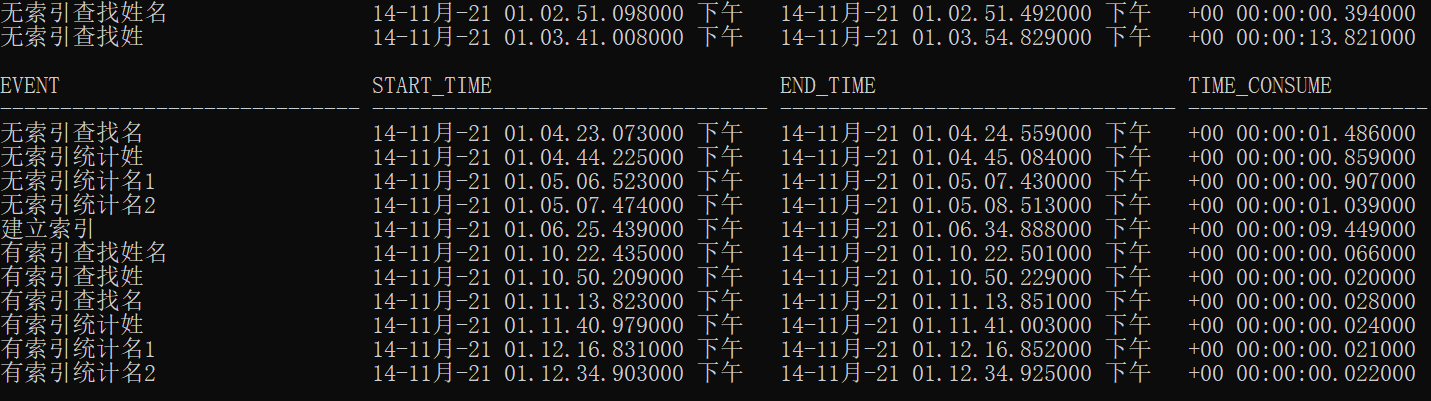
| 操作ID | 执行计划哈希值 | 访问方式 | 解释 |
|---|---|---|---|
| 无索引1 | 1542020857 | TABLE ACCESS FULL | 全盘扫描 |
| 无索引2 | 1542020857 | TABLE ACCESS FULL | 全盘扫描 |
| 无索引3 | 1542020857 | TABLE ACCESS FULL | 全盘扫描 |
| 无索引统计1 | 2811796169 | SORT AGGREGATE TABLE ACCESS FULL |
全盘扫描后聚合 |
| 无索引统计2 | 2811796169 | SORT AGGREGATE TABLE ACCESS FULL |
全盘扫描后聚合 |
| 有索引统计3 | 2811796169 | SORT AGGREGATE TABLE ACCESS FULL |
全盘扫描后聚合 |
| 有索引1 | 3803812383 | INDEX RANGE SCAN | 索引范围扫描 |
| 有索引2 | 3803812383 | INDEX RANGE SCAN | 索引范围扫描 |
| 有索引3 | 40889341 | INDEX FAST FULL SCAN | 索引快速扫描 |
| 有索引统计1 | 664314567 | SORT AGGREGATE INDEX FAST FULL SCAN |
快速扫描后聚合 |
| 有索引统计2 | 583658112 | SORT AGGREGATE INDEX FAST FULL SCAN |
快速扫描后聚合 |
| 有索引统计3 | 583658112 | SORT AGGREGATE INDEX FAST FULL SCAN |
快速扫描后聚合 |
结论:
- 无索引情况下前三个执行计划一致,后三个执行计划一致
- 使用索引范围扫描是因为使用一个索引存取多行数据
- 使用索引速度加快几十倍甚至上百倍
3. 5 分区对性能的影响
分学号首位ID统计人数与分专业(EF位)统计人数
分区建立前
set serveroutpu on;
set timing on;
set autotrace on;
drop index index_name_D312;
delete from t_time where event='无分区统计ID';
exec p_record_time_D312 ('无分区统计ID','start');
select count(*) from t_stud where sno like '5%';
exec p_record_time_D312 ('无分区统计ID','end');
delete from t_time where event='无分区统计专业';
exec p_record_time_D312 ('无分区统计专业','start');
select count(*) from t_stud where sno like '______08__';
exec p_record_time_D312 ('无分区统计专业','end');
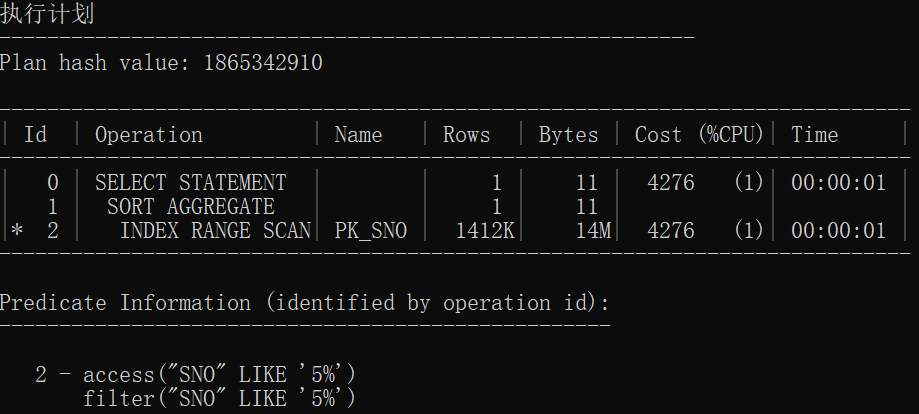
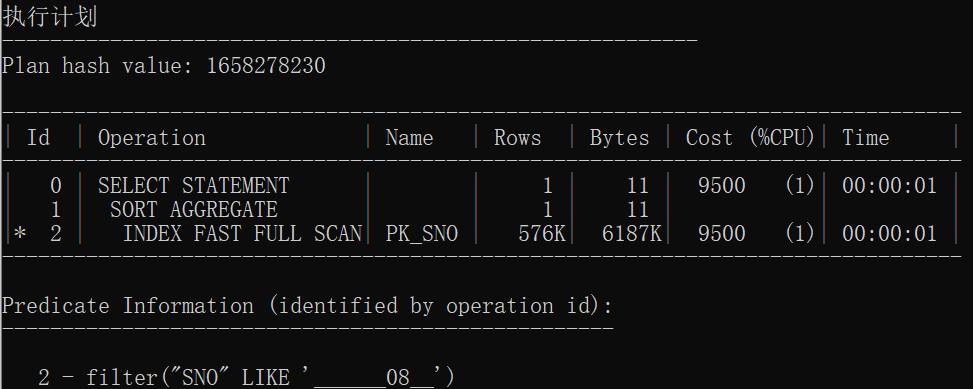
分区建立后
按学号首位建立10个分区分别为part_0到part_9
-- 建立分区
delete from t_time where event='建立分区表';
drop table t_pt_stud_info_D312;
exec p_record_time_D312 ('建立分区表','start');
create table t_pt_stud_info_D312(
sno varchar2(32) primary key,
sname varchar2(32),
sex varchar2(32) check(sex in('男', '女', '缺失')),
tel varchar2(32),
email varchar2(32) check(email like '%@%.%'),
birthday date check(birthday between date '1994-01-01' and date '1999-07-31')
)partition by range(sno) (
partition part_0 values less than ('1000190000'),
partition part_1 values less than ('2000190000'),
partition part_2 values less than ('3000190000'),
partition part_3 values less than ('4000190000'),
partition part_4 values less than ('5000190000'),
partition part_5 values less than ('6000190000'),
partition part_6 values less than ('7000190000'),
partition part_7 values less than ('8000190000'),
partition part_8 values less than ('9000190000'),
partition part_9 values less than (maxvalue)
);
drop synonym t_pt_stud;
create synonym t_pt_stud for t_pt_stud_info_D312;
insert into t_pt_stud
select
A.sno, B.name, C.sex, C.tel, C.email, C.birthday
from
(select t_sno_ab.*, rownum rn1 from t_sno_ab) A,
(select t_name.*, rownum rn2 from t_name) B,
(select t_random.*, rownum rn3 from t_random) C
where rn1 = rn2 and rn2 = rn3;
exec p_record_time_D312 ('建立分区表','end');
delete from t_time where event='有分区统计ID';
exec p_record_time_D312 ('有分区统计ID','start');
select count(*) from t_pt_stud where sno like '5%';
exec p_record_time_D312 ('有分区统计ID','end');
delete from t_time where event='有分区统计专业';
exec p_record_time_D312 ('有分区统计专业','start');
select count(*) from t_pt_stud where sno like '______08__';
exec p_record_time_D312 ('有分区统计专业','end');
select * from t_time order by start_time;
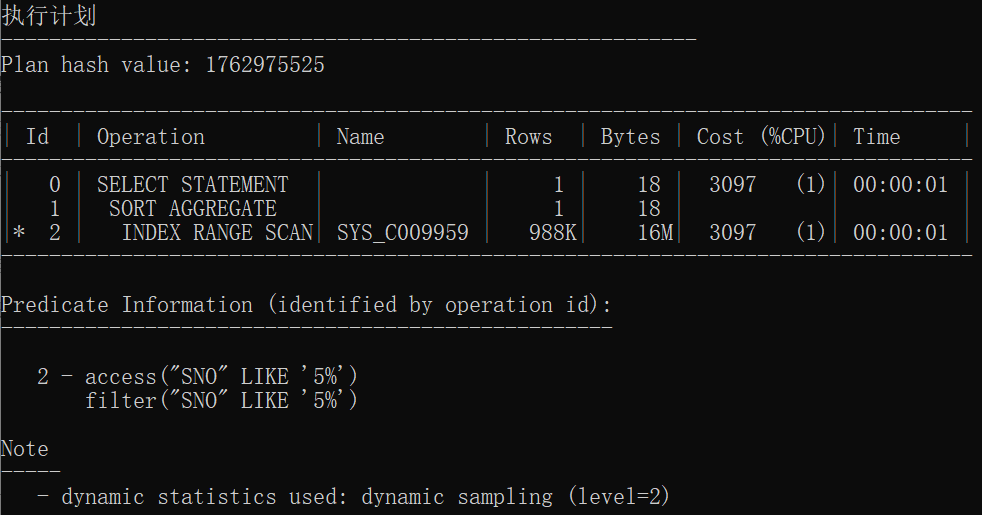
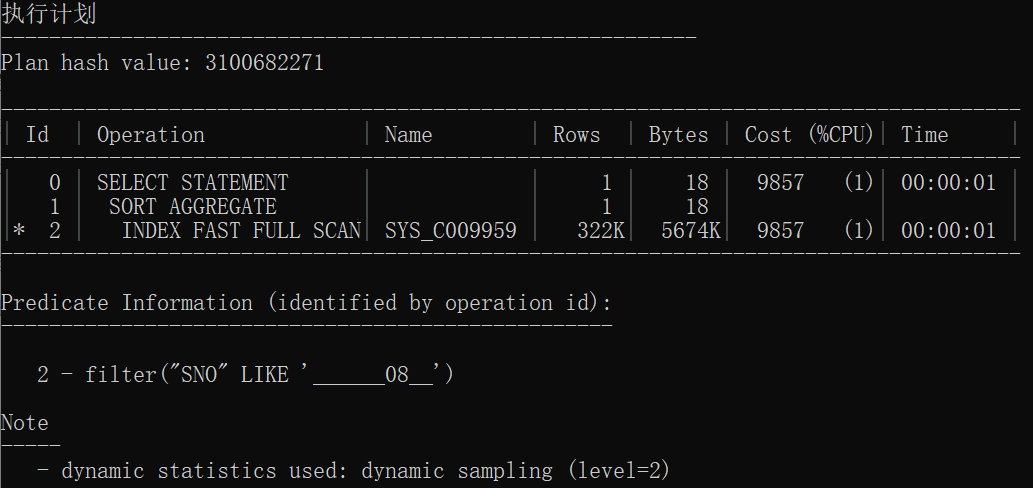

结论:在一定程度上分区表的速度比原始表更快
4. 收获总结
-
timestamp数据类型的使用:由于本次实验大部分操作需要统计时间,故手动实现一个统计时间的函数方便后续对比 -
学会使用
sqlloader导入外源数据:由于本次实验需要插入千万级数据,手动插入显然是不合适的。故采用专业工具sqlloader,写一个 .ctl 文件后实现批量导入 -
懂得了一些提高插入效率的方法
-
采用
/*+ append */ -
尽可能使用
insert+select的组合提升速率。这是因为优化器自动会处理成批处理的形式实现插入。 -
避免大量 LOOP 循环。在这里我使用了
select ... from xmltable('1 to 14400000');与select level from dual connect by level <= 32;避免手动实现 LOOP 循环 -
掌握了关于不同数据类型的一些基本操作
-
系统学习了如何读懂执行计划,并根据执行计划进行优化SQL语句
此外,在以下一些方面有一些收获
1. insert /*+append*/提速原因
- Data is appended to the end of the table, rather than attempting to use existing free space within the table.
- Data is written directly to the data files, by-passing the buffer cache.
- Referential integrity constraints are not considered.
- No trigger processing is performed.
2. 使用insert /*+append*/时,遇到了如下错误
ORA-12838: 无法在并行模式下修改之后读/修改对象
查询后学习到Oracle内部的两种模式
parallel: Data Manipulation Language (DML) operations such as INSERT, UPDATE, and DELETE can be parallelized by Oracle. Parallel execution can speed up large DML operations and is particularly advantageous in data warehousing environments where it's necessary to maintain large summary or historical tables.
Direct-load INSERT enhances performance during insert operations by formatting and writing data directly into Oracle datafiles, without using the buffer cache.
A major benefit of direct-load INSERT is that you can load data without logging redo or undo entries, which improves the insert performance significantly.
示例详见官方文档
关于报错的解释
Cause: Within the same transaction, an attempt was made to add read or modification statements on a table after it had been modified in parallel or with direct load. This is not permitted.
使用insert /*+append*/, 数据会直接写入数据文件
所以为保持事务一致性,要添加一个commit来修复这个bug
3. PK的存在不一定使 insert 操作变慢
Inserts are faster in a clustered table (but only in the "right" clustered table) than compared to a heap. The primary problem here is that lookups in the IAM/PFS to determine the insert location in a heap are slower than in a clustered table (where insert location is known, defined by the clustered key). Inserts are faster when inserted into a table where order is defined (CL) and where that order is ever-increasing.
So actually, having a good clustered index (e.g. on a INT IDENTITY column, if ever possible) does speed things up - even insert, updates and deletes!
==The speed will be faster only if the PK gets a clustered index==
详情见此处
5. 源码
set serveroutpu on;
set linesize 500;
-- 0.创建记录时间过程
drop table t_time_consume_D312;
create table t_time_consume_D312 (
event varchar2(128) primary key,
start_time timestamp,
end_time timestamp,
time_consume interval day to second
);
col event format a30;
col start_time format a33;
col end_time format a33;
col time_consume format a20;
drop synonym t_time;
create synonym t_time for t_time_consume_D312;
create or replace procedure p_record_time_D312
(
p_event in varchar2,
p_flag in varchar2
)
as
v_start_time timestamp;
v_end_time timestamp;
v_time interval day to second;
begin
if p_flag = 'start' then
-- 插入开始时间
select systimestamp into v_start_time from dual;
insert into t_time(event, start_time) values(p_event, v_start_time);
else
-- 更新终止时间与时间开销,打印输出
select systimestamp into v_end_time from dual;
select start_time into v_start_time from t_time where event = p_event;
select (v_end_time - v_start_time) day(2) to second into v_time from test;
update t_time set end_time = v_end_time, time_consume = v_time where event = p_event;
dbms_output.put_line(p_event || '耗时: ' || v_time);
end if;
end;
/
show error;
exec p_record_time_D312 ('demo','start');
-- 过若干秒
exec p_record_time_D312 ('demo','end');
select * from t_time;
-- 1. 导入姓名与相关数据
drop table t_name1;
create table t_name1(last_name varchar2(32));
drop table t_name2;
create table t_name2(first_name varchar2(32));
drop table t_common_name;
create table t_common_name(name varchar2(32));
------- load_last_name.ctl -------
LOAD DATA
INFILE 'D:\Messy\Experiment\last_name.CSV'
APPEND
INTO TABLE t_name1
FIELDS TERMINATED BY ','
(last_name)
------- cmd -------
sqlldr userid=C##U_LZC_D312/sys control='D:\Messy\Experiment\大型数据库\OraExp3_D312\load_last_name.ctl'
------- load_first_name.ctl -------
LOAD DATA
INFILE 'D:\Messy\Experiment\first_name.CSV'
APPEND
INTO TABLE t_name2
FIELDS TERMINATED BY ','
(first_name)
------- cmd -------
sqlldr userid=C##U_LZC_D312/sys control='D:\Messy\Experiment\大型数据库\OraExp3_D312\load_first_name.ctl'
------- load_common.ctl -------
OPTIONS(SKIP=1) --跳过第一行
LOAD DATA
INFILE 'D:\Messy\Experiment\common.CSV'
APPEND
INTO TABLE t_common_name
FIELDS TERMINATED BY ','
(virtual_column FILLER, name)
------- cmd -------
sqlldr userid=C##U_LZC_D312/sys control='D:\Messy\Experiment\大型数据库\OraExp3_D312\load_common.ctl'
-- 删去复姓
select count(*) from t_name1 where length(last_name) = 2;
delete from t_name1 where length(last_name) = 2;
select count(*) from t_name1;
-- 2. 创建姓名表
drop view v_name1;
drop view v_name2;
drop view v_name3;
-- 随机选择
delete from t_time where event='生成名字';
exec p_record_time_D312 ('生成名字','start');
create view v_name1 as select last_name n1 from (select distinct last_name from t_name1 order by dbms_random.value) where rownum <= 400;
create view v_name2 as select first_name n2 from (select distinct first_name from t_name2 order by dbms_random.value) where rownum <= 150;
create view v_name3 as select first_name n3 from (select distinct first_name from t_name2 order by dbms_random.value) where rownum <= 250;
set timing on;
set serveroutpu on;
-- 笛卡尔积
drop table t_name;
create table t_name as select n1 || n2 || n3 name from v_name1, v_name2, v_name3;
-- 插入常用姓名
insert into t_name select first_name from t_common_name;
exec p_record_time_D312 ('生成名字','end');
-- 3. 生成学号
exec p_record_time_D312 ('生成学号','start');
-- 存最终sno
drop table t_sno_ab;
drop table t_sno_cd;
drop table t_sno_ef;
drop table t_sno_gh;
-- 由于有前导0,故存成string,同时降低存储开销
create table t_sno_ab(sno varchar2(32));
create table t_sno_cd(sno number(8));
create table t_sno_ef(sno number(8));
create table t_sno_gh(sno number(2));
declare
i int;
begin
insert into t_sno_gh select level from dual connect by level <= 32;
for i in 1..50 loop
insert /*+ append */ into t_sno_ef select 190000+i*100+t_sno_gh.sno from t_sno_gh;
commit;
end loop;
for i in 1..90 loop
insert /*+ append */ into t_sno_cd select i*1000000+t_sno_ef.sno from t_sno_ef;
commit;
end loop;
for i in 1..80 loop
insert /*+ append */ into t_sno_ab select substr(10000000000+i*100000000+t_sno_cd.sno,2,10) from t_sno_cd;
commit;
end loop;
end;
/
exec p_record_time_D312 ('生成学号','end');
----------------- 一种更简便的写法 ------------------
exec p_record_time_D312 ('生成学号2','start');
-- 存最终sno
drop table t_sno_ab;
drop table t_sno_cd;
drop table t_sno_ef;
drop table t_sno_gh;
create table t_sno_ab(sno varchar2(32));
create table t_sno_cd(sno number(8));
create table t_sno_ef(sno number(8));
create table t_sno_gh(sno number(2));
insert /*+ append */ into t_sno_gh select level from dual connect by level <= 32;
commit;
insert /*+ append */ into t_sno_ef select 190000+i*100+t_sno_gh.sno from t_sno_gh, (select level i from dual connect by level <= 50);
commit;
insert /*+ append */ into t_sno_cd select i*1000000+t_sno_ef.sno from t_sno_ef, (select level i from dual connect by level <= 90);
commit;
insert /*+ append */ into t_sno_ab select substr(10000000000+i*100000000+t_sno_cd.sno,2,10) from t_sno_cd, (select level i from dual connect by level <= 80);
commit;
exec p_record_time_D312 ('生成学号2','end');
-- 4. 生成剩余随机字段
-- 性别
create or replace function f_get_sex return varchar2
as
v_num number;
v_sex varchar2(8);
begin
select dbms_random.value(1,1000) into v_num from dual;
if v_num < 498 then
v_sex := '男';
elsif v_num < 995 then
v_sex := '女';
else
v_sex := '缺失';
end if;
return v_sex;
end;
/
-- 电话
-- 辅助表:存储电话前三位
drop table t_tel_head;
create table t_tel_head(htel varchar2(4));
declare
type htel_array is varray(14) of t_tel_head.htel%type;
htels htel_array := htel_array('132', '135', '138', '139', '150', '151', '153', '156', '177', '178', '180', '183', '186', '188');
begin
for i in 1..14 loop
insert into t_tel_head values(htels(i));
end loop;
end;
/
select * from t_tel_head;
create or replace function f_get_tel return varchar2
is
v_tel varchar2(32);
v_htel varchar2(4);
v_ttel varchar2(16);
begin
-- 随机选一行模板
select htel into v_htel from (select htel from t_tel_head order by dbms_random.value ) where rownum = 1;
-- 随机生成剩余手机号
select substr(cast(dbms_random.value as varchar2(32)),5,8) into v_ttel from dual;
v_tel := v_htel || v_ttel;
return v_tel;
end;
/
show error;
-- 邮箱
-- 辅助表:常见邮箱
drop table t_email;
create table t_email_suffix(email_suffix varchar2(32));
declare
type email_suffix_array is varray(7) of t_email_suffix.email_suffix%type;
es email_suffix_array := email_suffix_array ('qq', 'gmail', 'ymail', '126', '169', 'outlook', 'csu');
begin
for i in 1..7 loop
insert into t_email_suffix values(es(i));
end loop;
end;
/
select * from t_email_suffix;
create or replace function f_get_email return varchar2
is
v_email_suffix varchar2(32);
v_email_head varchar2(32);
v_email varchar2(32);
begin
select email_suffix into v_email_suffix from (select email_suffix from t_email_suffix order by dbms_random.value ) where rownum = 1;
select substr(cast(dbms_random.value as varchar2(32)),4,11) into v_email_head from dual;
v_email := v_email_head || '@' || v_email_suffix || '.com';
return v_email;
end;
/
-- 生日
create or replace function f_get_birth return date
is
birth date;
begin
select to_date(
trunc(
dbms_random.value(to_char(date '1994-01-01', 'J'),
to_char(date '1999-07-31','J')
)
)
, 'J') into birth from dual;
return birth;
end;
/
-- 生成随机生成的字段
set timing on;
delete from t_time where event = '生成随机字段';
exec p_record_time_D312 ('生成随机字段','start');
drop table t_random;
create table t_random(
sex varchar2(32),
tel varchar2(32),
email varchar2(32),
birthday date
);
insert /*+ append */ into t_random NOLOGGING select f_get_sex(), f_get_tel(), f_get_email(), f_get_birth() from xmltable('1 to 14400000');
commit;
exec p_record_time_D312 ('生成随机字段','end');
-- 生成最终数据集
set timing on;
delete from t_time where event = '生成最终数据集';
exec p_record_time_D312 ('生成最终数据集','start');
-- 生成不含主键的学生信息表
drop table t_stud_info_D312;
create table t_stud_info_D312(
sno varchar2(32),
sname varchar2(32),
sex varchar2(32),
tel varchar2(32),
email varchar2(32),
birthday date
);
drop synonym t_stud;
create synonym t_stud for t_stud_info_D312;
insert into t_stud
select
A.sno, B.name, C.sex, C.tel, C.email, C.birthday
from
(select t_sno_ab.*, rownum rn1 from t_sno_ab) A,
(select t_name.*, rownum rn2 from t_name) B,
(select t_random.*, rownum rn3 from t_random) C
where rn1 = rn2 and rn2 = rn3;
exec p_record_time_D312 ('生成最终数据集','end');
-- 生成有主键的数据集
set timing on;
delete from t_time where event = '生成有主键最终数据集';
exec p_record_time_D312 ('生成有主键最终数据集','start');
-- 生成含主键的学生信息表
drop table t_pk_stud_info_D312;
create table t_pk_stud_info_D312(
sno varchar2(32) primary key,
sname varchar2(32),
sex varchar2(32),
tel varchar2(32),
email varchar2(32),
birthday date
);
drop synonym t_pk_stud;
create synonym t_pk_stud for t_pk_stud_info_D312;
insert into t_pk_stud
select
A.sno, B.name, C.sex, C.tel, C.email, C.birthday
from
(select t_sno_ab.*, rownum rn1 from t_sno_ab) A,
(select t_name.*, rownum rn2 from t_name) B,
(select t_random.*, rownum rn3 from t_random) C
where rn1 = rn2 and rn2 = rn3;
exec p_record_time_D312 ('生成有主键最终数据集','end');
-- 添加约束
exec p_record_time_D312 ('添加约束','start');
alter table t_stud_info_D312 add constraint pk_sno primary key(sno);
alter table t_stud_info_D312 add constraint ck_sex check(sex in ('男', '女', '缺失'));
alter table t_stud_info_D312 add constraint ck_email check(email like '%@%.%');
alter table t_stud_info_D312 add constraint ck_birth check(birthday between date '1994-01-01' and date '1999-07-31');
exec p_record_time_D312 ('添加约束','end');
-- 查询
set serveroutpu on;
set timing on;
set autotrace on;
delete from t_time where event='无索引查找姓名';
exec p_record_time_D312 ('无索引查找姓名','start');
select sname from t_stud where sname='叶令官';
exec p_record_time_D312 ('无索引查找姓名','end');
delete from t_time where event='无索引查找姓';
exec p_record_time_D312 ('无索引查找姓','start');
select sname from t_stud where sname like '叶__';
exec p_record_time_D312 ('无索引查找姓','end');
delete from t_time where event='无索引查找名';
exec p_record_time_D312 ('无索引查找名','start');
select sname from t_stud where sname like '_令官';
exec p_record_time_D312 ('无索引查找名','end');
delete from t_time where event='无索引统计姓';
exec p_record_time_D312 ('无索引统计姓','start');
select count(*) from t_stud where sname like '叶__';
exec p_record_time_D312 ('无索引统计姓','end');
delete from t_time where event='无索引统计名1';
exec p_record_time_D312 ('无索引统计名1','start');
select count(*) from t_stud where sname like '_令_';
exec p_record_time_D312 ('无索引统计名1','end');
delete from t_time where event='无索引统计名2';
exec p_record_time_D312 ('无索引统计名2','start');
select count(*) from t_stud where sname like '__官';
exec p_record_time_D312 ('无索引统计名2','end');
-- 建立索引
drop index index_name_D312;
delete from t_time where event='建立索引';
exec p_record_time_D312 ('建立索引','start');
create index index_name_D312 on t_stud_info_D312(sname);
exec p_record_time_D312 ('建立索引','end');
-- 查询
set serveroutpu on;
set timing on;
set autotrace on;
delete from t_time where event='有索引查找姓名';
exec p_record_time_D312 ('有索引查找姓名','start');
select sname from t_stud where sname='叶令官';
exec p_record_time_D312 ('有索引查找姓名','end');
delete from t_time where event='有索引查找姓';
exec p_record_time_D312 ('有索引查找姓','start');
select sname from t_stud where sname like '叶__';
exec p_record_time_D312 ('有索引查找姓','end');
delete from t_time where event='有索引查找名';
exec p_record_time_D312 ('有索引查找名','start');
select sname from t_stud where sname like '_令官';
exec p_record_time_D312 ('有索引查找名','end');
delete from t_time where event='有索引统计姓';
exec p_record_time_D312 ('有索引统计姓','start');
select count(*) from t_stud where sname like '叶__';
exec p_record_time_D312 ('有索引统计姓','end');
delete from t_time where event='有索引统计名1';
exec p_record_time_D312 ('有索引统计名1','start');
select count(*) from t_stud where sname like '_令_';
exec p_record_time_D312 ('有索引统计名1','end');
delete from t_time where event='有索引统计名2';
exec p_record_time_D312 ('有索引统计名2','start');
select count(*) from t_stud where sname like '__官';
exec p_record_time_D312 ('有索引统计名2','end');
set autotrace off;
set serveroutpu on;
set timing on;
set autotrace on;
drop index index_name_D312;
exec p_record_time_D312 ('无分区统计ID','start');
select count(*) from t_stud where sno like '5%';
exec p_record_time_D312 ('无分区统计ID','end');
exec p_record_time_D312 ('无分区统计专业','start');
select count(*) from t_stud where sno like '______08__';
exec p_record_time_D312 ('无分区统计专业','end');
-- 建立分区
delete from t_time where event='建立分区表';
drop table t_pt_stud_info_D312;
exec p_record_time_D312 ('建立分区表','start');
create table t_pt_stud_info_D312(
sno varchar2(32) primary key,
sname varchar2(32),
sex varchar2(32) check(sex in('男', '女', '缺失')),
tel varchar2(32),
email varchar2(32) check(email like '%@%.%'),
birthday date check(birthday between date '1994-01-01' and date '1999-07-31')
)partition by range(sno) (
partition part_0 values less than ('1000190000'),
partition part_1 values less than ('2000190000'),
partition part_2 values less than ('3000190000'),
partition part_3 values less than ('4000190000'),
partition part_4 values less than ('5000190000'),
partition part_5 values less than ('6000190000'),
partition part_6 values less than ('7000190000'),
partition part_7 values less than ('8000190000'),
partition part_8 values less than ('9000190000'),
partition part_9 values less than (maxvalue)
);
drop synonym t_pt_stud;
create synonym t_pt_stud for t_pt_stud_info_D312;
insert into t_pt_stud
select
A.sno, B.name, C.sex, C.tel, C.email, C.birthday
from
(select t_sno_ab.*, rownum rn1 from t_sno_ab) A,
(select t_name.*, rownum rn2 from t_name) B,
(select t_random.*, rownum rn3 from t_random) C
where rn1 = rn2 and rn2 = rn3;
exec p_record_time_D312 ('建立分区表','end');
exec p_record_time_D312 ('有分区统计ID','start');
select count(*) from t_pt_stud where sno like '5%';
exec p_record_time_D312 ('有分区统计ID','end');
exec p_record_time_D312 ('有分区统计专业','start');
select count(*) from t_pt_stud where sno like '______08__';
exec p_record_time_D312 ('有分区统计专业','end');