Advanced
事务
1. 概念
A transaction is a logical, atomic unit of work that contains one or more SQL statements.
A transaction groups SQL statements so that they are either all committed, which means they are applied to the database, or all rolled back, which means they are undone from the database. Oracle Database assigns every transaction a unique identifier called a transaction ID.
所有的Oracle事务都要遵循ACID四个属性
Atomicity:要么都执行,要么都不执行;例如一个事务要更新100行,但在更新20行后系统宕机了,那么数据库会回滚到20行之前的状态
Consistency:事务将数据库从一种一致状态转换为另一种一致状态;即时刻保持数据的一致性;例如上述例子
Isolation:在提交事务之前,该事务的效果对其他事务是不可见的。例如,更新 hr.employees 表的一个用户看不到另一用户同时对该表进行的未提交的更改。因此,在用户看来,事务好像是串行执行的。
Durability:已提交事务所做的更改是永久性的。事务完成后,数据库通过其恢复机制确保事务中的更改不会丢失。
2. 操作
只读事务
- 该时间点的数据冻结,不允许执行DML操作
- 别的会话引起数据的改变不会影响到它
set transaction read only;
-- 或
exec dbms_transaction.read_only;
读写事务
set transaction read write;
设置回滚段程序代码
set transaction use rollback segment xxx;
提交事务
commit;
-- 或
set autocommit on;
回滚事务
set savepoint sp0; -- sqlplus中只能savepoint sp0;
...
rollback to sp0; -- sp0后面的操作全部回滚
3. COMMIT
- 提交前,你看通过查询 the modified tables 看到该事务中所涉及的所有变化,但别的用户看不到;提交后别的用户也看得到了
- 提交前你可以回滚所有的 change
- 结束当前事务,并使事务中执行的所有更改永久化(别的用户也看得到)
- 消除了事务中所有的 savepoints 并释放 locks
4. Read Phenomena
The SQL standard defines three read phenomena; issues that can occur when many people read and write to the same rows. These are:
- Dirty reads
- Non-repeatable (or fuzzy) reads
- Phantom reads
Dirty reads
A dirty read is when you see uncommitted rows in another transaction. There is no guarantee the other transaction will commit. So when these are possible, you could return data that was never saved to the database!
Dirty reads are impossible in Oracle Database. You can only view uncommitted rows in your own transaction.
Non-repeatable (or Fuzzy) reads
A non-repeatable read is when selecting the same row twice returns different results. This happens when someone else updates the row between queries.

The SQL standard also allows for fuzzy reads in a single query.
This can cause problems when swapping values for two rows. If the other session updates these part way through your query, you can double count values. In this example, the bricks table has 20,000 rows, with a 50:50 split between red and blue.
The first transaction counts how many rows there are of each colour. Halfway through the second query it has counted 5,000 rows of each. At this point, another transaction updates the colour of all the rows to red.
In databases without statement-level consistency (语句级别的一致性,可以理解为一条语句要么全部执行,要么全不执行), the query could see these values immediately. This leads it to count the remaining 10,000 rows as red. So the query returns 5,000 blue rows and 15,000 red. A total that never existed in the table!
Luckily Oracle Database always has statement-level consistency. Fuzzy reads are impossible in one query.
Oracle always enforces statement-level read consistency.
This guarantees that all the data returned by a single query comes from a single point in time—the time that the query began.
Therefore, a query never sees dirty data or any of the changes made by transactions that commit during query execution.
As query execution proceeds, only data committed before the query began is visible to the query. The query does not see changes committed after statement execution begins.
Phantom Reads
A phantom read is a special case of fuzzy reads. This happens when another session inserts or deletes rows that match the where clause of your query. So repeated queries can return different rows:
As with fuzzy reads, these are impossible in a single statement in Oracle Database.

5. Transaction Isolation Levels
| Dirty Reads | Non-repeatable Reads | Phantom Reads | |
|---|---|---|---|
| Read Uncommitted | ✔ | ✔ | ✔ |
| Read Committed | ✘ | ✔ | ✔ |
| Repeatable Reads | ✘ | ✘ | ✔ |
| Serializable | ✘ | ✘ | ✘ |
Read Uncommitted
Oracle里没有实现这种模式;不可能出现在Oracle
Read Committed
This is the default mode for Oracle Database.
Using read committed, you have statement-level consistency.
This means that each DML command (select, insert, update, or delete) can see all the data saved before it begins. Any changes saved by other sessions after it starts are hidden.
So none of the read phenomena are possible in a single statement in Oracle Database. Only within a transaction.
Repeatable Read
The intent of repeatable read in the SQL standard is to provide consistent results from a query. But Oracle Database already has this in read committed! So it has no use for this level and doesn't implement it.
Serializable
You use this in Oracle Database to get transaction-level consistency .
You can only view changes committed in the database at the time your transaction starts.
Any changes made by other transactions after this are hidden from your transaction.
即开始事务后,其他的事务造成的影响都看不到
系统改变号
系统改变 (SCN) 是 Oracle 数据库使用的逻辑内部时间戳。
SCN 对数据库中发生的事件进行排序,这是满足事务的 ACID 属性所必需的。
更改 SCN 的事件是对一个特定内部函数的调用。
SCN 保证在正常操作下增加。不能保证号码是连续的(缺少号码)。
与流行的看法相反,它不会仅在提交时生成
查看当前SCN:
select current_scn from V$database;
CURRENT_SCN
-----------
1123790
通过下面例子我们可以看到,随着每次执行,SCN 的数量都会增加。通过查询视图 V$DATABASE,我们实际上导致了 SCN 号的跳转。
SQL> select current_scn from V$database;
CURRENT_SCN
-----------
1178883
SQL> /
CURRENT_SCN
-----------
1178885
SQL> /
CURRENT_SCN
-----------
1178886
检查点
1. 原因
通常数据库都是在提交(COMMIT)完成之前要先保证 Redo 日志条目都被写入到日志文件中,才会给用户反馈提交完成的通知(Commit complete)
而保存在 Buffer Cache 中的脏块会不定期地、分批地写入到数据文件中。
也就是说,commit 的时候日志就写入了,但数据不一定写入,即修改的数据并不是在用户提交后就立马写入数据文件中。
这样就存在一个问题,当数据库崩溃的时候并不能保证 Buffer Cache 里面的脏数据全部写入到数据文件中,那么在实例启动的时候就要使用日志文件进行恢复操作,将数据库恢复到崩溃之前的状态,从而保证数据的一致性。
那怎么确定该从何时、从哪里开始恢复呢,Oracle 使用了检查点(Checkpoint)来进行确定。
2. 概念
A checkpoint is an operation that Oracle performs to ensure data file consistency. When a checkpoint occurs, Oracle ensures all modified buffers are written from the data buffer to disk files.
Checkpoint checks every three seconds to see whether the amount of memory exceeds the value of the PGA_AGGREGATE_LIMIT parameter,and if so,takes action.
Checkpointing is an important Oracle activity which records the highest system change number (SCN) so that all data blocks less than or equal to the SCN are known to be written out to the data files.
If there is a failure and then subsequent cache recovery, only the redo records containing changes at SCN(s) higher than the checkpoint need to be applied during recovery.
一般所说的检查点是一种将内存中的已修改数据块与磁盘上的数据文件进行同步的数据库事件(Event)
检查点信息(Checkpoint Information)包含检查点位置(Checkpoint Position)、SCN、联机Redo日志中开始恢复的位置等
在Redo日志流中记录的SCN号是在进行数据库实例恢复时的起始位置
检查点位置(Checkpoint Position)是一种数据结构,由在数据缓冲池中存在的最老的脏数据位置决定,并且检查点信息。
检查点信息存储在控制文件和数据文件头中。
控制文件中记录的检查点位置是实例恢复的起点。在检查点位置前的Redo记录,其对应的Buffer Cache中的Dirty Buffer已经被写进了数据文件,在此位置后的Redo记录,所对应数据脏块有可能还在内存中。如果发生了实例崩溃,只需要在日志文件中找到检查点位置(Low Cache RBA),从此处开始应用所有的Redo日志文件,就完成了前滚操作。
当检查点发生时,CKPT通知DBWn进程将脏块(Dirty Buffer)写出到数据文件上,并更新数据文件头及控制文件上的检查点信息。
注意,CKPT进程不负责Buffer Cache中的脏数据写入到磁盘中,该工作由DBWn负责;CKPT进程也不负责将Redo Log Buffer中的数据写入到联机Redo日志文件中,该工作由LGWR负责。
由于Oracle事务在提交的时候不会将已修改数据块同步写入磁盘上,所以,CKPT进程负责更新控制文件和数据文件头的检查点信息和触发DBWn写脏数据到磁盘。CKPT执行越频繁,DBWn写出就越频繁。
设置检查点(checkpoint),一旦时间到,强制将BUFFER写入磁盘;这样redo的时候,只需要redo最近的一个检查点之后的; 多久设置一个检查点?需要根据系统确定
3. 作用
检查点的主要目的是以对数据库的日常操作影响最小的方式刷新脏块,检查点主要有两个作用:
- 确保数据库的一致性,包含两个方面
- 确保Buffer Cache中的Dirty Buffer能有规律地定期写入磁盘,这样在系统或数据库出现故障时就不会丢失数据
- 确保数据库在一致性关闭期间可以将所有已提交了的数据写入磁盘
- 实现更快的数据库恢复,主要是缩短实例恢复的时间。实例恢复要把实例异常关闭前没有写出到硬盘的脏数据通过日志进行恢复,只需要重新应用控制文件中记录的检查点位置之后的联机Redo日志条目即可进行恢复。如果脏块过多,那么实例恢复的时间也会很长,所以,检查点的发生可以减少脏块的数量,从而提高实例恢复的时间。
备份

1. 归档模式
当一个重做日志写满或 DBA 发出 switch log 命令的时候会发生日志切换
如果 oracle 运行在非归档模式下,oracle 直接覆盖写下一个重做日志组。如果 oracle 运行在归档模式下则 oracle 会查询即将写入的重做日志是否归档,没有归档则等待其归档,等归档完成以后再覆盖写入重做日志记录。
归档模式优点
- 可以进行完全、不完全恢复:对于数据库所作的全部改动 都记录在日志文件中,如果发生磁盘故障等导致数据文件丢失的话,则可以利用物理备份和归档日志完全恢复数据库,不会丢失任何数据
- 可以进行联机热备,能够增量备份
归档模式缺点
- 需要更多的磁盘空间来保存归档日志
- 需要定期维护归档表空间和备份归档日志
非归档模式缺点
- 只能进行脱机备份(因为有可能边备份边覆盖?同时对一个日志文件进行写操作?lock?)
- 必须备份整个数据库,不能备份部分数据库
- 不能增量备份,对于 TB 级别的数据库(VLDB),将是个很大的缺点。
- 只能部分恢复,如果数据文件丢失,只能恢复最后一次的完全备份,而之后的所有数据库改变将全部丢失
查看是否处于归档模式
-- SYS 用户登录
Archive log list
-- 数据字典查看
SELECT dbid,name,log_mode,platform_name FROM v$database;
设置模式
-- 关闭数据库
shutdown
-- 重启实例
startup mount;
-- 设置归档模式
alter database archivelog;
-- open 数据库
alter database open;
-- 将重做日志归档
archive log all;
2. 备份分类
物理备份与逻辑备份
- Physical backups, which are the primary concern in a backup and recovery strategy, are copies of physical database files. You can make physical backups with either the Recovery Manager (RMAN) utility or operating system utilities.
- Logical backups contain logical data (for example, tables and stored procedures) extracted with an Oracle utility and stored in a binary file. You can use logical backups to supplement physical backups.
一致性备份(冷备/脱机备份)与非一致性备份(热备/联机备份)
- A consistent backup is one in which the files being backed up contain all changes up to the same system change number (SCN). This means that the files in the backup contain all the data taken from a same point in time. Unlike an inconsistent backup, a consistent whole database backup does not require recovery after it is restored.
The only way to make a consistent whole database backup is to shut down the database with the NORMAL, IMMEDIATE, or TRANSACTIONAL options and make the backup while the database is closed.
- An inconsistent backup is a backup in which the files being backed up do not contain all the changes made at all the SCNs. In other words, some changes are missing. This means that the files in the backup contain data taken from different points in time. This can occur because the datafiles are being modified as backups are being taken.
Oracle recovery makes inconsistent backups consistent by reading all archived and online redo logs, starting with the earliest SCN in any of the datafile headers, and applying the changes from the logs back into the datafiles.
冷备份指数据库关闭时的物理备份
热备份指数据库运行时的物理备份
关于“热备为什么要在归档模式下”:因为非归档只能做脱机备份;而热备是联机备份
备份实例
热备份
-- 1.使数据库处于 ARCHIVELOG 模式
-- 以 sysdba 登录
conn C##U_LZC_D312/sys as sysdba;
-- 关闭数据库
shutdown;
-- mount 数据库
startup mount;
-- 启动归档模式
alter database archivelog;
-- 2.备份表空间中的数据文件
-- 查看表空间有哪些
select tablespace_name from dba_tablespaces;
-- 查看USERS表空间存在哪个文件
select file_name from dba_data_files where tablespace_name = 'USERS';
FILE_NAME
-------------------------------------------
E:\APP\LEMONADE\ORADATA\LZCORCL\USERS01.DBF
-- 使USERS表空间处于备份模式
alter tablespace USERS begin backup;
------ RMAN ------
-- 让USERS表空间退出备份模式
alter tablespace USERS end backup;
-- 归档当前日志文件
alter system switch logfile;
-- 另开一个cmd,启动rman
rman target SYSTEM/sys nocatalog;
-- 输入备份归档日志文件命令
backup archivelog all ;
完成 backup 于 21-12月-21
启动 Control File and SPFILE Autobackup 于 21-12月-21
段 handle=E:\APP\LEMONADE\FAST_RECOVERY_AREA\LZCORCL\AUTOBACKUP\2021_12_21\O1_MF_S_1091918475_JW3SWCJB_.BKP comment=NONE
完成 Control File and SPFILE Autobackup 于 21-12月-21
-- 在原来黑框框备份控制文件
alter database backup controlfile to 'mybackup' reuse;--....
Bind Variables
Oracle执行一个语句的时候,会生成最优的执行计划。但它会先在shared pool看是否有执行过一样的语句,这样就不用再生成计划。下面这三个计划就是不同的。
SELECT fname, lname, pcode FROM cust WHERE id = 674;
SELECT fname, lname, pcode FROM cust WHERE id = 234;
SELECT fname, lname, pcode FROM cust WHERE id = 332;
但是如果改写成这样
SELECT fname, lname, pcode FROM cust WHERE id = :cust_no;
那么就是相同的计划,可以直接使用。这里的:cust_no就是bind variable
1. SQL*Plus里 使用 Bind Variable
variable sno varchar2(32)
exec :sno := '8208191312'
select * from t_attend where sno = :sno;
print sno; -- 或 print :sno;
-- 接下来PL/SQL里面可以使用sqlplus里面声明的:sno
declare
v_sno varchar2(32);
begin
v_sno := :sno;
select sno into :sno from t_stud_D312 where sno='8208191312';
end;
declare
v_mname varchar2(32);
begin
select mname into v_mname from t_major_D312 where majorno='00';
select mname into :v_mname from t_major_D312 where majorno='08'; -- 会在sqlplus里面看有没有声明绑定变量
dbms_output.put_line(v_mname); -- 计科
dbms_output.put_line(:v_mname);-- 大数据
end;
2. PL/SQL 里使用 Bind Variable
事实上PL/SQL会自动处理为 Bind Variable
create or replace procedure dsal(p_empno in number)
as
begin
update emp
set sal=sal*2
where empno = p_empno;
commit;
end;
/
3. 动态SQL里使用Bind Variable
这里才一般会考虑要不要以及如何改写为 Bind Variable
-- 不使用
create or replace procedure dsal(p_empno in number)
as
begin
execute immediate
'update emp set sal = sal*2 where empno = '||p_empno;
commit;
end;
-- 使用
create or replace procedure dsal(p_empno in number)
as
begin
execute immediate
'update emp set
sal = sal*2 where empno = :x' using p_empno;
commit;
end;
https://blogs.oracle.com/sql/post/improve-sql-query-performance-by-using-bind-variables
https://www.akadia.com/services/ora_bind_variables.html
动态SQL语句
1. EXECUTE语句
str_xxx里面出现的引号全改为两个单引号using的变量值可以是绑定变量、或变量或常量均可returning into数量一定要对应- 不可以对 table name 等使用绑定变量
execute immediate 'str_xxx';
-- into
execute immediate 'str_xxx'
into var_1, var_2;
-- using的变量值可以是绑定变量、或变量或常量均可
-- using 1个变量
str_stm ='delete from t_xxx where id=:x'; -- x充当占位符
execute immediate str_stm using v_id;
-- using 多个变量
declare
v_id varchar2(32):='8208191312';
v_status varchar2(32):='正常';
str_stm varchar2(128);
begin
str_stm :='delete from t_attend where sno=:x and status=:y';
execute immediate str_stm using v_id, v_status;
end;
/
-- plsql块
str_stm := '
begin
... -- 这里也可以有execute
end
';
execute immediate str_stm;
-- returning into
str_stm := 'update t_xxx set xxx=xxx where... returning... '
execute immediate str_stm returning into v_xxx;
2. OPEN-FOR 语句
set serveroutpu on;
declare
str_stm varchar2(128);
v_sno varchar2(32):='8208191312';
v_rec t_attend%rowtype;
type type_xxx is ref cursor;
v_cur type_xxx;
begin
str_stm:='select * from t_attend where sno=:x';
open v_cur for str_stm using v_sno; -- 动态SQL
loop
fetch v_cur into v_rec;
dbms_output.put_line(v_rec.sno);
exit when v_cur%notfound;
end loop;
close v_cur;
end;
3. 批量SQL
declare
str_stm1 varchar2(128);
str_stm2 varchar2(128);
v_major varchar2(32) := '08';
type t_status is table of varchar2(32) index by binary_integer;
v_status_tab t_status;
type t_sno is table of varchar2(32) index by binary_integer;
v_sno_tab t_sno;
begin
str_stm1 := 'select sno, status from t_attend where majorno=:x';
execute immediate str_stm1 bulk collect into v_sno_tab, v_status_tab using v_major;
v_major := '08';
str_stm2 := 'update t_attend set status=''正常'' where majorno = :x returning sno, status into :tmp1, :tmp2';
-- tmp前面必须有:
-- tmp1 tmp2 可以不声明
execute immediate str_stm2 using v_major returning bulk collect into v_sno_tab, v_status_tab;
for i in 1..v_sno_tab.count loop
dbms_output.put_line(v_sno_tab(i) || '--' || v_status_tab(i));
end loop;
end;
关于绑定变量问题
:x:占位符作用,在using子句中应用:v_xxx:说明是bind variable,会寻找是否有该绑定变量
declare
str1 varchar2(128);
str21 varchar2(128);
str22 varchar2(128);
str23 varchar2(128);
str3 varchar2(128);
v_sno varchar2(32) := '8208191312';
v_mname varchar2(32) := 'nothing';
v_status varchar2(32);
begin
-- 内部变量必须带: 当表示占位符时
-- using此时必须在sqlplus里声明该绑定变量
-- using也可以不跟:,说明是普通变量
str1 := 'select * from t_attend where sno=:x';
execute immediate str1 using v_sno;
-- select xxx into :xxx ...此处冒号不可省略
str21 := 'select mname into :v_mname from t_major_D312 where majorno=''08''';
execute immediate str21;
dbms_output.put_line(v_mname); -- nothing
str22 := 'select mname into :never_declare from t_major_D312 where majorno=''08''';
execute immediate str22;
dbms_output.put_line(v_mname); -- nothing
-- dbms_output.put_line(:never_declare); -- 报错
-- 此时 print never_declare 也显示不存在
str23 := 'select mname into v_mname from t_major_D312 where majorno=''08''';
-- execute immediate str23; -- 报错:缺失关键字
dbms_output.put_line(v_mname); -- nothing
-- returning into ... 与using一样
-- 可以跟:,此时必须在sqlplus里声明该绑定变量
-- 也可以不跟:,说明是普通变量
str3 := 'update t_major_D312 set mname=''大数据2'' where majorno = ''08'' returning mname into :x';
execute immediate str3 returning into v_status;
dbms_output.put_line(v_status);
end;
Direct-Load INSERT
直接写入磁盘的两种方式
parallel: Data Manipulation Language (DML) operations such as INSERT, UPDATE, and DELETE can be parallelized by Oracle. Parallel execution can speed up large DML operations and is particularly advantageous in data warehousing environments where it's necessary to maintain large summary or historical tables.
With a parallel INSERT, atomicity of the transaction is ensured. Atomicity cannot be guaranteed if multiple parallel loads are used. Also, parallel load could leave some table indexes in an "Unusable" state at the end of the load if errors occurred while updating the indexes. In comparison, parallel INSERT atomically updates the table and indexes (that is, it rolls back the statement if errors occur while updating the index).
Direct-load INSERT enhances performance during insert operations by formatting and writing data directly into Oracle datafiles, without using the buffer cache.
A major benefit of direct-load INSERT is that you can load data without logging redo or undo entries, which improves the insert performance significantly.
示例详见官方文档
补充1:
insert /*+append*/提速原因:
The APPEND hint tells the optimizer to perform a direct-path insert, which improves the performance of INSERT .. SELECT operations for a number of reasons:
- Data is appended to the end of the table, rather than attempting to use existing free space within the table.
- Data is written directly to the data files, by-passing the buffer cache.
- Referential integrity constraints are not considered.
- No trigger processing is performed.
The combination of these features make direct-path inserts significantly quicker than conventional-path inserts.
补充2:
insert /*+append*/时,关于 ORA-12838: 无法在并行模式下修改之后读/修改对象 的解释
Cause: Within the same transaction, an attempt was made to add read or modification statements on a table after it had been modified in parallel or with direct load. This is not permitted.
所以为保持事务一致性,要添加一个commit来修复这个bug
执行计划
执行计划是一条查询语句在 Oracle 中的执行过程或访问路径的描述
1. 概念
Recursive Calls:递归调用- 执行SQL语句时,额外执行的操作或语句
- 例如:DDL语句,触发器
Db Block Gets:当前读Consistent Gets:一致性读,在回滚段读Logical Reads:逻辑读- Logical Reads= Db Block Gets+ Consistent Gets
Physical Reads:物理读,从磁盘读取到内存Row Source:行源,即从哪查询Predicate:谓词,即where限制条件Concatenated Index:组合索引leading column:引导列Selectivity:可选择性- 某列上,唯一键的数量/表中的行数
Driving Table:驱动表/外层表Probed Table:被探查表/内层表
2. Oracle优化器
Oracle中的优化器是SQL分析和执行的优化工具,它负责生成、制定SQL的执行计划。
Oracle的优化器有两种:
- RBO(Rule-Based Optimization) 基于规则的优化器
- CBO(Cost-Based Optimization) 基于代价的优化器
RBO:
RBO有严格的使用规则,只要按照这套规则去写SQL语句,无论数据表中的内容怎样,也不会影响到你的执行计划;
换句话说,RBO对数据“不敏感”,它要求SQL编写人员必须要了解各项细则;
RBO一直沿用至ORACLE 9i,从ORACLE 10g开始,RBO已经彻底被抛弃。
CBO:
CBO是一种比RBO更加合理、可靠的优化器,在ORACLE 10g中完全取代RBO;
CBO通过计算各种可能的执行计划的“代价”,即COST,从中选用COST最低的执行方案作为实际运行方案;
它依赖数据库对象的统计信息,统计信息的准确与否会影响CBO做出最优的选择,也就是对数据“敏感”。
3. 读表
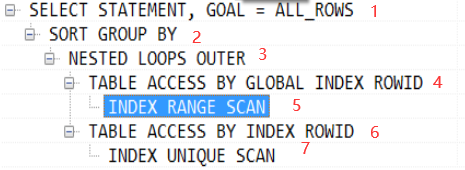
3. 1 执行顺序
- 根据Operation缩进来判断,缩进最多的最先执行;(缩进相同时,最上面的最先执行)--> 4,6先执行
- 同一级如果某个动作没有子ID就最先执行
- 同一级的动作执行时遵循最上最右先执行的原则 --> 4比6先执行,5比7..
故上述执行顺序为:5 4 7 6 3 2 1
3. 2 动作说明
3. 2. 1 访问表方式
上图中 TABLE ACCESS BY … 即描述的是该动作执行时表访问(或者说Oracle访问数据)的方式;
表访问的几种方式:(非全部)
- TABLE ACCESS FULL(全表扫描)
- TABLE ACCESS BY ROWID(通过ROWID的表存取)
- TABLE ACCESS BY INDEX SCAN(索引扫描)
TABLE ACCESS FULL(全表扫描)
读取表中所有的行,检查每一行是否满足 SQL 语句中的 Where 限制条件
全表扫描时可以使用多块读(即一次I/O读取多块数据块)操作,提升吞吐量;
使用建议:数据量太大的表不建议使用全表扫描,除非本身需要取出的数据较多,占到表数据总量的 5% ~ 10% 或以上
TABLE ACCESS BY ROWID(通过ROWID的表存取)
行的ROWID指出了该行所在的数据文件、数据块以及行在该块中的位置,所以通过ROWID可以快速定位到目标数据上,这也是Oracle中存取单行数据最快的方法;
TABLE ACCESS BY INDEX SCAN(索引扫描)
- 扫描索引得到对应的ROWID
- 通过ROWID定位到具体的行读取数据
索引扫描又分为5种
- INDEX UNIQUE SCAN(索引唯一扫描)
- INDEX RANGE SCAN(索引范围扫描)
- INDEX FULL SCAN(索引全扫描)
- INDEX FAST FULL SCAN(索引快速扫描)
- INDEX SKIP SCAN(索引跳跃扫描)
INDEX UNIQUE SCAN(索引唯一扫描)
每次至多只返回一条记录;
表中某字段存在 UNIQUE、PRIMARY KEY 约束时,Oracle常实现唯一性扫描;
INDEX RANGE SCAN(索引范围扫描)
使用一个索引存取多行数据
发生索引范围扫描的三种情况:
- 在唯一索引列上使用了范围操作符(如:> < <> >= <= between)
- 在组合索引上,只使用部分列进行查询(查询时必须包含前导列,否则会走全表扫描)
- 对非唯一索引列上进行的任何查询
INDEX FULL SCAN(索引全扫描)
进行全索引扫描时,查询出的数据都必须从索引中可以直接得到(注意全索引扫描只有在CBO模式下才有效)
INDEX FAST FULL SCAN(索引快速扫描)
扫描索引中的所有的数据块,与 INDEX FULL SCAN 类似,但是一个显著的区别是它不对查询出的数据进行排序(即数据不是以排序顺序被返回)
INDEX SKIP SCAN(索引跳跃扫描):
Oracle 9i后提供,有时候复合索引的前导列(索引包含的第一列)没有在查询语句中出现,oralce也会使用该复合索引,这时候就使用的INDEX SKIP SCAN;
什么时候会触发 INDEX SKIP SCAN 呢?
前提条件:表有一个复合索引,且在查询时有除了前导列(索引中第一列)外的其他列作为条件,并且优化器模式为CBO时
当Oracle发现前导列的唯一值个数很少时,会将每个唯一值都作为常规扫描的入口,在此基础上做一次查找,最后合并这些查询;
例如:
假设表emp有ename(雇员名称)、job(职位名)、sex(性别)三个字段,并且建立了如 create index idx_emp on emp (sex, ename, job) 的复合索引;
因为性别只有 '男' 和 '女' 两个值,所以为了提高索引的利用率,Oracle可将这个复合索引拆成 ('男', ename, job),('女', ename, job) 这两个复合索引;
当查询 select * from emp where job = 'Programmer' 时,该查询发出后:
Oracle先进入sex为'男'的入口,这时候使用到了 ('男', ename, job) 这条复合索引,查找 job = 'Programmer' 的条目;
再进入sex为'女'的入口,这时候使用到了 ('女', ename, job) 这条复合索引,查找 job = 'Programmer' 的条目;
最后合并查询到的来自两个入口的结果集。
3. 2. 2 表连接方式
驱动表与匹配表
驱动表(Driving Table):表连接时首先存取的表,又称外层表(Outer Table),这个概念用于 NESTED LOOPS(嵌套循环) 与 HASH JOIN(哈希连接)中;
如果驱动表返回较多的行数据,则对所有的后续操作有负面影响,故一般选择小表(应用Where限制条件后返回较少行数的表)作为驱动表。
匹配表(Probed Table):又称为内层表(Inner Table),从驱动表获取一行具体数据后,会到该表中寻找符合连接条件的行。故该表一般为大表(应用Where限制条件后返回较多行数的表)。
例如
假设T_USERSERVICEINFO是个大表,有4000万数据,占有100万个块;而T_USERINFO是个小表,有4000条数据,占有100个块。
(1)以大表为驱动表去要访问的数据块:对T_USERSERVICEINFO全表扫描需要访问100万个块,而T_USERSERVICEINFO中的每一条数据都需要全表扫描T_USERINFO一次,需要访问40亿个块(4000万100),总共访问(40亿+100万*)个块。
(2)以小表为驱动表去要访问的数据块:对T_USERINFO全表扫描需要访问100个块,而T_USERINFO中的每一条数据都需要全表扫描T_USERSERVICEINFO一次,需要访问40亿个块(4000*100万),总共访问(40亿个块。
从上面的计算看,当两个表都是全表扫描时,选择小表做驱动表相对好些。不过,两者的查询代价都太大,都是不能接受的,因为内表的数据被访问了N遍(N为驱动表的数据量),这是严重的浪费。
表连接几种方式
- SORT MERGE JOIN(排序-合并连接)
- NESTED LOOPS(嵌套循环)
- HASH JOIN(哈希连接)
- CARTESIAN PRODUCT(笛卡尔积)
注:这里将首先存取的表称作 row source 1,将之后参与连接的表称作 row source 2;
SORT MERGE JOIN(排序-合并连接):
假设有查询:select a.name, b.name from table_A a join table_B b on (a.id = b.id)
内部连接过程:
a) 生成 row source 1 需要的数据,按照连接操作关联列(如示例中的a.id)对这些数据进行排序
b) 生成 row source 2 需要的数据,按照与 a) 中对应的连接操作关联列(b.id)对数据进行排序
c) 两边已排序的行放在一起执行合并操作(对两边的数据集进行扫描并判断是否连接)
延伸:
如果示例中的连接操作关联列 a.id,b.id 之前就已经被排过序了的话,连接速度便可大大提高,因为排序是很费时间和资源的操作,尤其对于有大量数据的表。
故可以考虑在 a.id,b.id 上建立索引让其能预先排好序。不过遗憾的是,由于返回的结果集中包括所有字段,所以通常的执行计划中,即使连接列存在索引,也不会进入到执行计划中,除非进行一些特定列处理(如仅仅只查询有索引的列等)。
排序-合并连接的表无驱动顺序,谁在前面都可以;
排序-合并连接适用的连接条件有: < <= = > >= ,不适用的连接条件有: <> like
NESTED LOOPS(嵌套循环):
内部连接过程:
a) 取出 row source 1 的 row 1(第一行数据),遍历 row source 2 的所有行并检查是否有匹配的,取出匹配的行放入结果集中
b) 取出 row source 1 的 row 2(第二行数据),遍历 row source 2 的所有行并检查是否有匹配的,取出匹配的行放入结果集中
c) ……
若 row source 1 (即驱动表)中返回了 N 行数据,则 row source 2 也相应的会被全表遍历 N 次。
因为 row source 1 的每一行都会去匹配 row source 2 的所有行,所以当 row source 1 返回的行数尽可能少并且能高效访问 row source 2(如建立适当的索引)时,效率较高。
延伸:
嵌套循环的表有驱动顺序,注意选择合适的驱动表。
嵌套循环连接有一个其他连接方式没有的好处是:可以先返回已经连接的行,而不必等所有的连接操作处理完才返回数据,这样可以实现快速响应。
应尽可能使用限制条件(Where过滤条件)使驱动表(row source 1)返回的行数尽可能少,同时在匹配表(row source 2)的连接操作关联列上建立唯一索引(UNIQUE INDEX)或是选择性较好的非唯一索引,此时嵌套循环连接的执行效率会变得很高。若驱动表返回的行数较多,即使匹配表连接操作关联列上存在索引,连接效率也不会很高。
HASH JOIN(哈希连接) :
哈希连接只适用于等值连接(即连接条件为 = )
HASH JOIN对两个表做连接时并不一定是都进行全表扫描,其并不限制表访问方式;
内部连接过程简述:
a) 取出 row source 1(驱动表,在HASH JOIN中又称为Build Table) 的数据集,然后将其构建成内存中的一个 Hash Table(Hash函数的Hash KEY就是连接操作关联列),创建Hash位图(bitmap)
b) 取出 row source 2(匹配表)的数据集,对其中的每一条数据的连接操作关联列使用相同的Hash函数并找到对应的 a) 里的数据在 Hash Table 中的位置,在该位置上检查能否找到匹配的数据
HASH JOIN的三种模式:
- OPTIMAL HASH JOIN
- ONEPASS HASH JOIN
- MULTIPASS HASH JOIN
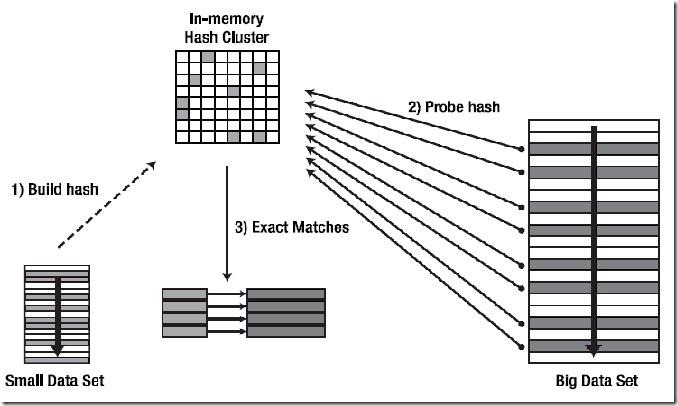
OPTIMAL HASH JOIN:
OPTIMAL 模式是从驱动表(也称Build Table)上获取的结果集比较小,可以把根据结果集构建的整个Hash Table都建立在用户可以使用的内存区域里。
连接过程简述:
Ⅰ:首先对Build Table内各行数据的连接操作关联列使用Hash函数,把Build Table的结果集构建成内存中的Hash Table。如图所示,可以把Hash Table看作内存中的一块大的方形区域,里面有很多的小格子,Build Table里的数据就分散分布在这些小格子中,而这些小格子就是Hash Bucket。
Ⅱ:开始读取匹配表(Probed Table)的数据,对其中每行数据的连接操作关联列都使用同上的Hash函数,定位Build Table里使用Hash函数后具有相同值数据所在的Hash Bucket。
Ⅲ:定位到具体的Hash Bucket后,先检查Bucket里是否有数据,没有的话就马上丢掉匹配表(Probed Table)的这一行。如果里面有数据,则继续检查里面的数据(驱动表的数据)是否和匹配表的数据相匹配。
ONEPASS HASH JOIN :
从驱动表(也称Build Table)上获取的结果集较大,无法将根据结果集构建的Hash Table全部放入内存中时,会使用 ONEPASS 模式。
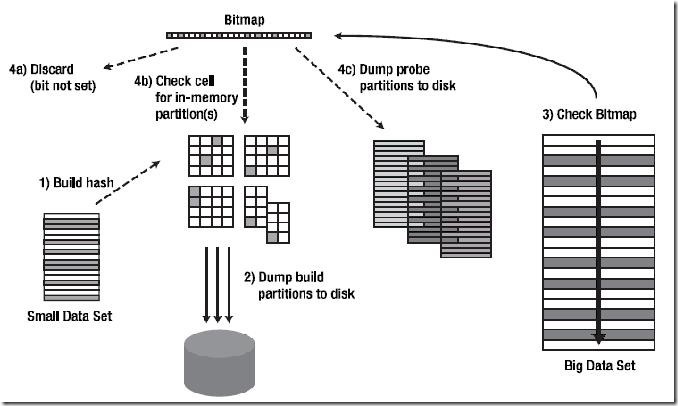
连接过程简述:
Ⅰ:由于内存无法放下所有的Hash Table内容,将导致有的Hash Bucket放在内存里,有的Hash Bucket放在磁盘上,无论放在内存里还是磁盘里,Oracle都使用一个Bitmap结构来反映这些Hash Bucket的状态(包括其位置和是否有数据)。
Ⅱ:读取匹配表数据并对每行的连接操作关联列使用同上的Hash函数,定位Bitmap上Build Table里使用Hash函数后具有相同值数据所在的Bucket。如果该Bucket为空,则丢弃匹配表的这条数据。如果不为空,则需要看该Bucket是在内存里还是在磁盘上。
如果在内存中,就直接访问这个Bucket并检查其中的数据是否匹配,有匹配的话就返回这条查询结果。
如果在磁盘上,就先把这条待匹配数据放到一边,将其先暂存在内存里,等以后积累了一定量的这样的待匹配数据后,再批量的把这些数据写入到磁盘上(上图中的 Dump probe partitions to disk)。
Ⅲ:当把匹配表完整的扫描了一遍后,可能已经返回了一部分匹配的数据了。接下来还有Hash Table中一部分在磁盘上的Hash Bucket数据以及匹配表中部分被写入到磁盘上的待匹配数据未处理,现在Oracle会把磁盘上的这两部分数据重新匹配一次,然后返回最终的查询结果。
MULTIPASS HASH JOIN:
当内存特别小或者相对而言Hash Table的数据特别大时,会使用 MULTIPASS 模式。MULTIPASS会多次读取磁盘数据,应尽量避免使用该模式。
Read Phenomena & Isolation Levels
On Transaction Isolation Levels(更深入)
Oracle System Change Number: An Introduction
【DB笔试面试532】在Oracle中,什么是检查点?如何调优检查点?
http://blog.itpub.net/25542870/viewspace-2144766/
https://betgar.github.io/2018/04/16/oracle-bind-variable/
https://docs.oracle.com/cd/A81042_01/DOC/sqlplus.816/a75664/ch34.htm