一、实验目的
-
理解鸢尾花数据集的结构;
-
掌握R语言利用机器学习算法进行处理的流程和语法;
-
掌握R语言数据可视化的基本方法;
-
掌握机器学习模型的建立与模型选择的方法;
-
掌握常用的机器学习算法在鸢尾花数据集上的应用。
二、实验环境
Windows系统,RGui(32-bit)
三、实验内容
鸢尾花(Iris)数据集是常用的分类实验数据集,由Fisher, 1936收集整理。数据集包含150个数据,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。本实验对鸢尾花数据各个特征的相关性进行分析,接下来实验几种常用的机器学习算法对该数据进行分类的效果,最后选出分类效果较好的方法。
四、实验步骤结果及分析
4.1. 安装caret包
加载caret包:
install.packages("caret")
library(caret)
4.2.查看鸢尾花数据
4.3.数据集分成两部分
其中80%将用于训练我们的模型,20%我们将作为验证数据集。
生成验证数据集
train_list <- sample(nrow(iris), 0.7*nrow(iris))
test <- iris[-train_list,]
生成训练数据集
train <- iris[train_list,]
4.4.查看数据集的属性
4.4.1数据集的维度(用dim函数)。
> dim(iris)
[1] 150 5
150个数据,5个维度
4.4.2属性的类型。
sapply(iris, class)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
"numeric" "numeric" "numeric" "numeric" "factor"
数据的5个维度的属性分别是:数字,数字,数字,数字,因子
4.4.3窥视数据本身(head函数)。
head(iris)
4.4.4鸢尾花中class属性的级别(levels()函数)。
> a <- factor(iris$Species)
> levels(a)
[1] "setosa" "versicolor" "virginica"
级别有三个,分别是"setosa" "versicolor" "virginica"
4.4.5鸢尾花类别占比情况
解释该行作用
percentage <- prop.table(table(dataset$Species)) * 100
求出iris数据集的Species属性中每种取值的所占的百分比,赋予percetage变量。
解释该行作用
cbind(freq=table(dataset$Species), percentage=percentage)
将iris的Species属性每种取值的频数和所占的百分比的表格按照列进行拼接。
4.6所有属性的统计摘要(用summary函数)
summary(iris)

获取每个属性的最小值,四分位数,最大值。
4.5.数据可视化
4.5.1 单变量图
解释下面每条语句的作用
# x input,y output
x <- dataset[,1:4]
y <- dataset[,5]
将iris数据集的前四列提取出来赋给x
将iris数据集的第五列提取出来赋给y
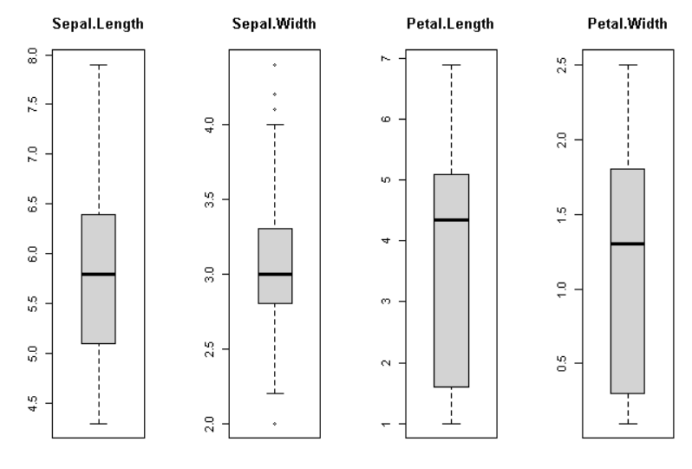
```r par(mfrow=c(1,4))
for(i in 1:4) {
boxplot(x[,i], main=names(iris)[i])
} ```
par()函数将画图区域分割为4个;
在每个分区里分别画iris数据集每一列的箱线图
plot(y)
将y中每个值的频数画成柱状图
4.5.2 多变量图
解释下面每条语句的作用并回答下面的问题
# scatterplot matrix
#featurePlot(x=x, y=y, plot="ellipse")
#featurePlot(x=x, y=y, plot="box")
featurePlot(x=x[y\=="setosa",1:2], y=y[y=="setosa"], plot="ellipse")
featurePlot(x=x[y\=="versicolor",1:2], y=y[y=="versicolor"], plot="ellipse")
featurePlot(x=x[y\=="virginica",1:2], y=y[y=="virginica"], plot="ellipse")
分别画出品种为setosa、versicolor、virginica的鸢尾花的花萼长度与花萼宽度的关系图,说明三种花的花萼长度和宽度都大致成正相关关系
r
featurePlot(x=x[,1:2], y=y, plot="density")
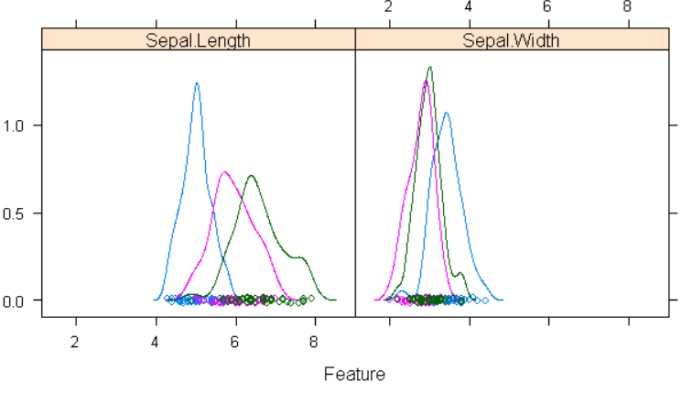
画出三种花的花萼长度、花萼宽度的分布图。可以看出三种花的花萼长度分布差别较为明显,花萼宽度分别差别不太明显。
思考? 如何知道什么线条表示的是那种类型?蓝色表示“setosa”;红色表示“versicolor”;绿色表示“virginica”
答:
可以分别运行如下指令:
featurePlot(x=x[y\=="setosa",1:2], y=y[y=="setosa"], plot="density")
featurePlot(x=x[y\=="versicolor",1:2], y=y[y=="versicolor"], plot="density")
featurePlot(x=x[y\=="virginica",1:2], y=y[y=="virginica"], plot="density")
分别画出setosa、versicolor、virginica线条,发现三条线条的颜色分别是蓝色、粉色、绿色,说明蓝色表示“setosa”;红色表示“versicolor”;绿色表示“virginica”。
各个图片横纵坐标的含义是什么?
在椭圆图上Sepal.length是第一列的横坐标和第四行的纵坐标
在密度图上是Sepal.Length和Sepal.Width的值
4.6.算法评估
以下是我们将在此步骤中涵盖的内容:
1.设置测试工具以使用10倍交叉验证。
2.建立5种不同的模型, 依据鸢尾花花萼和花瓣的测量结果对其所属种种类进行预测.
3.选择最佳的模型。
4.6.1 10倍交叉验证
用10倍交叉验证来估计准确性。
将数据集分成10个部分,9个训练和1个测试,所有可能组合都用来训练模型。
control <- trainControl(method="cv", number=10)
metric <- "Accuracy"
4.6.2 建立模型
我们不知道哪个算法可以解决此问题或使用哪些设置。我们从上面图中某些类在某些维度上可以部分线性分离,因此我们期望得到普遍良好的结果。
我们来评估5种不同的算法:
线性判别分析(LDA)
分类和回归树(CART)。
k-最近邻居(kNN)。
带有线性内核的支持向量机(SVM)。
随机森林(RF)
1) #### 线性判别分析(LDA)
解释下面每条语句的作用
set.seed(7)
fit.lda <- train(Species~., data=dataset, method="lda", metric=metric, trControl=control)
设置随机种子为7
用lda方法来训练模型,通过iris数据集的前四列来预测Species属性。
-
分类和回归树(CART)
解释下面每条语句的作用
set.seed(7)
fit.cart <- train(Species~., data=dataset, method="rpart", metric=metric, trControl=control)
设置随机种子为7
用分类和回归树方法来训练模型,通过iris数据集的前四列来预测Species属性。
3) #### k-最近邻居(kNN)
解释下面每条语句的作用
set.seed(7)
fit.knn <- train(Species~., data=dataset, method="knn", metric=metric, trControl=control)
设置随机种子为7
用 k-最近邻居方法来训练模型,通过iris数据集的前四列来预测Species属性。
4) #### 带有线性内核的支持向量机(SVM)
解释下面每条语句的作用
set.seed(7)
fit.svm <- train(Species~., data=dataset, method="svmRadial", metric=metric, trControl=control)
设置随机种子为7
用带有线性内核的支持向量机方法来训练模型,通过iris数据集的前四列来预测Species属性。
5) #### 随机森林(RF)
解释下面每条语句的作用
```R set.seed(7)
fit.rf <- train(Species~., data=dataset, method="rf", metric=metric, trControl=control) ```
设置随机种子为7
用随机森林方法来训练模型,通过iris数据集的前四列来预测Species属性。
4.6.3选择最佳模型
现在每个都有5个模型和精度估算。我们需要将模型相互比较并选择最准确的模型。
可以通过首先创建所创建模型的列表并使用summary() 函数显示每个模型的准确性。
解释下面每条语句的作用
results <- resamples(list(lda=fit.lda, cart=fit.cart, knn=fit.knn, svm=fit.svm, rf=fit.rf))
summary(results)
创建一个汇总表:
调用summary()函数,并传入resamples()函数值。它会创建一个表格,每行是一种算法,每列是评估指标。
将模型的准确率画图显示
dotplot(results)
#对结果进行说明分析
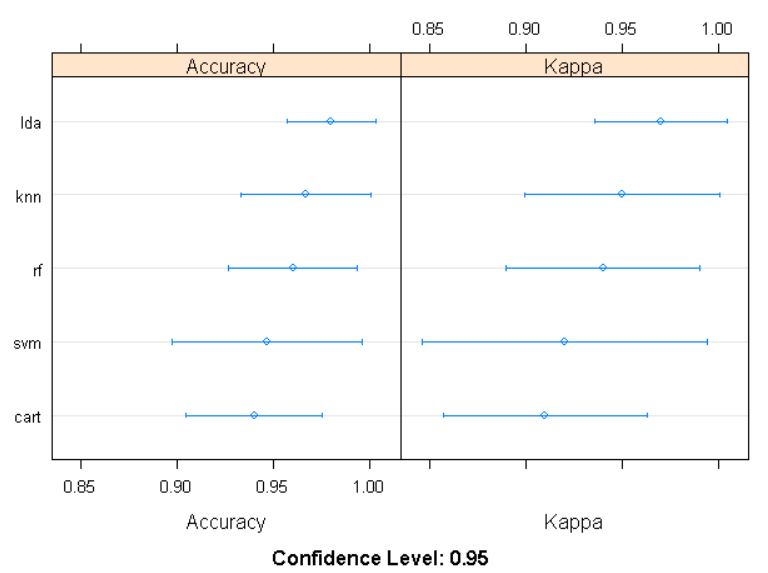
由图中可知,预测准确度和训练结果的好坏(Kappa值)从大到小分别是: lda , knn , rf , svm , cart 。
模型的置信度为0.95。
可以看到在这种情况下最准确的模型是LDA:
查看LDA模型的情况:
> print(fit.lda)
Linear Discriminant Analysis
150 samples
4 predictor
3 classes: 'setosa', 'versicolor', 'virginica'
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 135, 135, 135, 135, 135, 135, ...
Resampling results:
Accuracy Kappa
0.98 0.97
lda预测的准确度为0.98,kappa检验值为0.97,接近1,说明训练效果很好。
4.7.做出预测
直接在验证集上运行LDA模型,并在混淆矩阵中总结结果。
```R predictions <- predict(fit.lda, validation)
confusionMatrix(predictions, validation$Species) ```
结果如下:
Class: setosa Class: versicolor Class: virginica
Sensitivity 1.0000 0.9600 0.9800
Specificity 1.0000 0.9900 0.9800
Pos Pred Value 1.0000 0.9796 0.9608
Neg Pred Value 1.0000 0.9802 0.9899
Prevalence 0.3333 0.3333 0.3333
Detection Rate 0.3333 0.3200 0.3267
Detection Prevalence 0.3333 0.3267 0.3400
Balanced Accuracy 1.0000 0.9750 0.9800
对各种参数进行解释:
| 参数 | 解释 |
|---|---|
| Sensitivity | 预测为正实际占正的比例 |
| Specificity | 预估为负实际为负的比例 |
| Pos Pred Value | 真阳率,实际为正占预测为正的比例 |
| Neg Pred Value | 真阴率,实际为负占预测为负的比例 |
| Prevalence | 预测结果中真实正样本占总样本的比例 |
| Detection Rate | 检出率,预测为正正样本占所有样本的比率 |
| Detection Prevalence | 预测为正占总样本的比率 |
| Balanced Accuracy | (真阳率+真阴率)/2 |
从混淆矩阵中可以看出,预测准确率都能达到97.5%以上,说明预测结果非常好。